I am an ardent believer in The Headless Web, that is the interaction points that your users will have with the web will not be in the traditional browser but deeply integrated on the users device via things like notifications and cards, in webviews and services, and on new types of devices and in ways that we can’t yet imagine and as a developer all you do is build for the web. It will still be powered by HTML and JS, but the interaction points may not be the renderer we know today.
Two things happened in the last week that led me on the path that I am about to explain:
- I found a docker image in our slack made by Justin Ribeiro (he is also one of our awesome Web Google Developer Experts) that would host a headless version of Chrome.
- Google announced actions for Assistant.
With these two things, I wanted to put my preaching in to practice. I’ve a Google Home right next to me and it annoys me when it says it can’t open web pages yet.
My plan was simple:
- Host Chrome on a server
- Host a frontend that connects to Chrome
- Read back the accessiblity tree. Screen readers have been doing this for years, it must be simple…. Right?
I got there! Kinda.
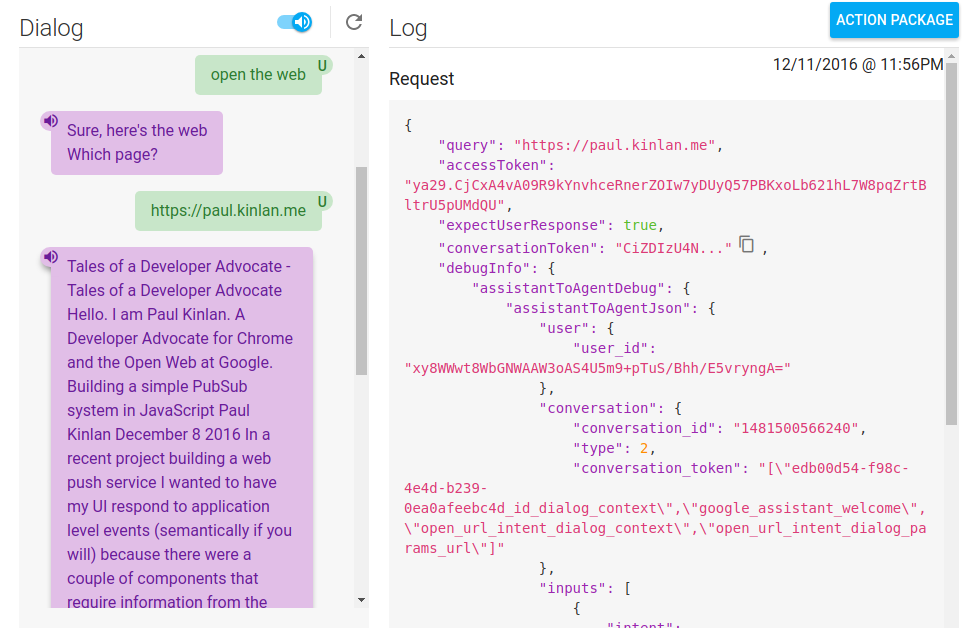
In my POC I had no intention of providing the interactivity that you would expect from a screen reader. It would just read the title and the body of important text of the page, it would not offer navigation or form interactivity.
To get started with the Assistant integration I used API.ai which lets you define the types of queries you want to parse and how they are roughly structured it will then pass this through to a service of your choice (via a webhook) so that you can respond accordingly.
The architecture I created was not overly complex. I have a frontend that is running headless chrome and services requests from API.ai (API.ai did all the hard work), it would then open up a tab, load the page and then introspect the page to get the critical information on that page that I can format and pass back to API.ai.
To host headless Chrome I used Justin Riberio’s Headless Chrome Docker file and the rest of the architecture is as follows:
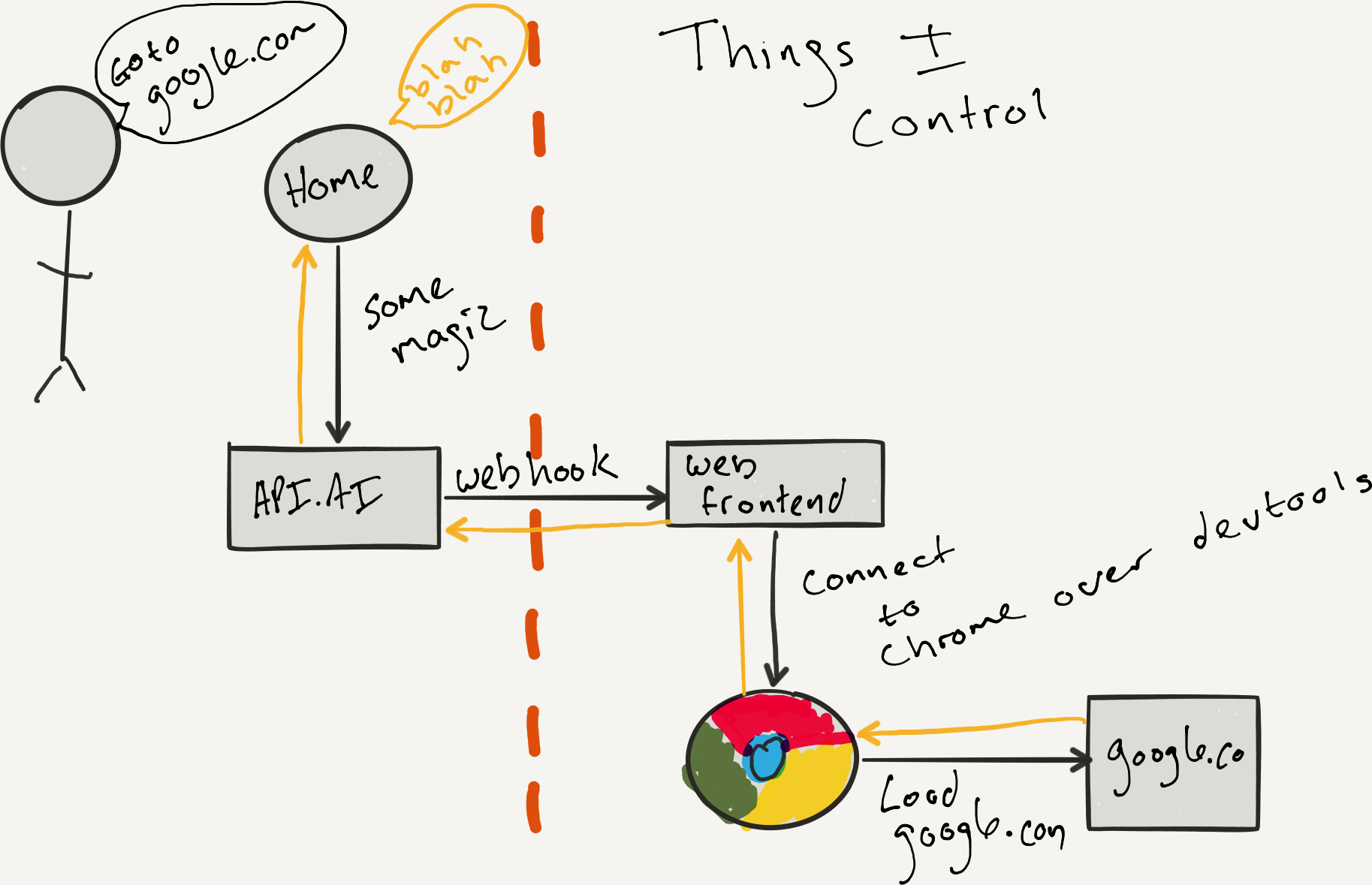
To connect to Chrome I used the Chrome DevTools protocol via the chrome-remote-interface
module.
For each incoming request from API.ai I create a new Chrome tab and then load a page into it.
chrome.New((err, tab) => {
if (!err) {
console.log(tab);
}
chrome(tab, instance => {
instance.Page.loadEventFired(render.bind(this, instance, res));
instance.Page.enable();
instance.once('ready', () => {
instance.Page.navigate({ url: url });
});
instance.once('error', (err) => {
console.error(err);
res.json({
"speech": "Sorry, there was an error",
"displayText": "Sorry, there was an error",
"source": "Paul Kinlan"
});
instance.close();
});
})
});
Once you have opened the tab, you need to then read the page. Inspecting the page isn’t too hard but the DevTools protocol can be a little esoteric (you can’t easily get access to the DOM elements properties).
const DOMProperties = {};
const render = (instance, res) => {
return instance.DOM.getDocument(-1).then(document => {
const title = getTitle(instance, document)
.catch(error => error )
.then(title => DOMProperties.title = title )
const body = getBody(instance, document)
.catch(error => error)
.then(body => DOMProperties.body = body )
Promise.all([title, body])
.then(() => {
res.json({
"speech": `${DOMProperties.title}\n\n${DOMProperties.body}`,
"displayText": `${DOMProperties.title}\n\n${DOMProperties.body}`,
"source": "Paul Kinlan"
});
})
.then(() => {
instance.close();
})
});
};
const getTitle = function(instance, document) {
return instance.DOM.querySelector({'nodeId': document.root.nodeId, 'selector': 'title'})
.then(node => instance.DOM.resolveNode(node))
.then(node => instance.Runtime.getProperties(node.object))
.then(properties => properties.result.find(el => el.name == 'text').value.value);
}
const getBody = function(instance, document) {
return instance.DOM.querySelector({'nodeId': document.root.nodeId, 'selector': 'body'})
.then(node => instance.DOM.resolveNode(node))
.then(node => instance.Runtime.getProperties(node.object))
.then(properties => properties.result.find(el => el.name == 'innerText').value.value);
}
In my case I just needed to get the title of the page and the entire body text and then craft that into a response that API.ai can understand. It took me a while to get this far mostly because the documentation for all aspects is a little lacking and I had to learn how to use API.ai (docs are decent) and how to get Chrome hosted on a public server via AppEngine.
One of the big thoughts you will all have is that this is a bit of a Rube Goldberg machine — Hosting Chrome on a server just to get the body of the page to the screen. I did have a couple of good reasons why:
- I had planned on taking advantage of many years of accessibility research and using the underlying A11Y tree to help me render the page as a voice, however it was a pretty complex beast and I couldn’t get access to everything.
- Many pages require JavaScript now just to load and I wanted to be able to parse them and read the text back
- Many pages load additional content in after the load and I don’t want to miss that.
- It was an incredibly interesting exercise and I can pull a lot more data out about the page (for instance I can send an screen shot back to the user)
I don’t intend to productionize this as it is just a demo, but I do think that it has a huge amount of potential and I’ve learned many things along the way.
- Wow, AppEngine Flexible containers are amazing. Docker -> Scale! This is my set up (https://github.com/paulkinlan/chromeonhome) and in theory it can Scale!
- API.ai is pretty awesome at parsing text and speech in to a relative sane model that is easy to parse
- API.ai has a 5 second timeout for web hooks and lots of pages haven’t loaded in that time :)
- I didn’t know there is an approval process for Google Home and Assistant. Makes sense I suppose but it’s incredibly frustrating.
I am more than ever convinced that the future of the web is not only on the
surfaces that we know today, but also all around us in the devices we use. If we
can cleanly integrate Forms, navigation and structure we can expose even more
functionality out to integrations that are not our point, touch and click based
interfaces. This is why I am interested to dive more into the A11Y tree to see
if there is other information that can be used in interesting ways.
I am looking forward to seeing the services that can be built when you have a web browser in your web server. This is just one example.
Major thanks go to Zackary Chapple and Justin Riberio. Without their early experimentation and putting it on the web I would not have got this far in such short time.
Thanks to Surma on my team for suggesting App Engine Flexible containers!


Paul Kinlan
Trying to make the web and developers better.




