Ich hatte nach Google IO eine kurze Ausfallzeit und wollte einen lang anhaltenden Juckreiz bekommen, den ich hatte. Ich möchte nur Text kopieren können, der in Bildern im Browser enthalten ist. Das ist alles. Ich denke, es wäre eine nette Sache für alle.
Es ist nicht einfach, Funktionen direkt in Chrome einzufügen, aber ich weiß, dass ich das Intent-System unter Android nutzen kann und das jetzt über das Web (oder zumindest Chrome unter Android).
Zwei neue Ergänzungen zur Webplattform - Share Target Level 2 (oder wie ich es gerne nenne File Share) und TextDetector in der Shape Detection API - have allowed me to build a utility that I can Share images to and get the text held inside them .
Die grundlegende Implementierung ist relativ einfach. Sie erstellen ein Freigabeziel und einen Handler im Service Worker. Sobald Sie das vom Benutzer freigegebene Image haben, führen Sie TextDetector darauf aus.
Mit Share Target API kann Ihre Webanwendung Teil des Subsystems für die native Freigabe sein. In diesem Fall können Sie sich jetzt für die Verarbeitung aller image/* Typen registrieren, indem Sie diese in Web App Manifest wie folgt deklarieren.
"share_target": {
"action": "/index.html",
"method": "POST",
"enctype": "multipart/form-data",
"params": {
"files": [
{
"name": "file",
"accept": ["image/*"]
}
]
}
}
Wenn Ihr PWA installiert ist, sehen Sie es an allen Orten, an denen Sie Bilder freigeben, wie folgt:
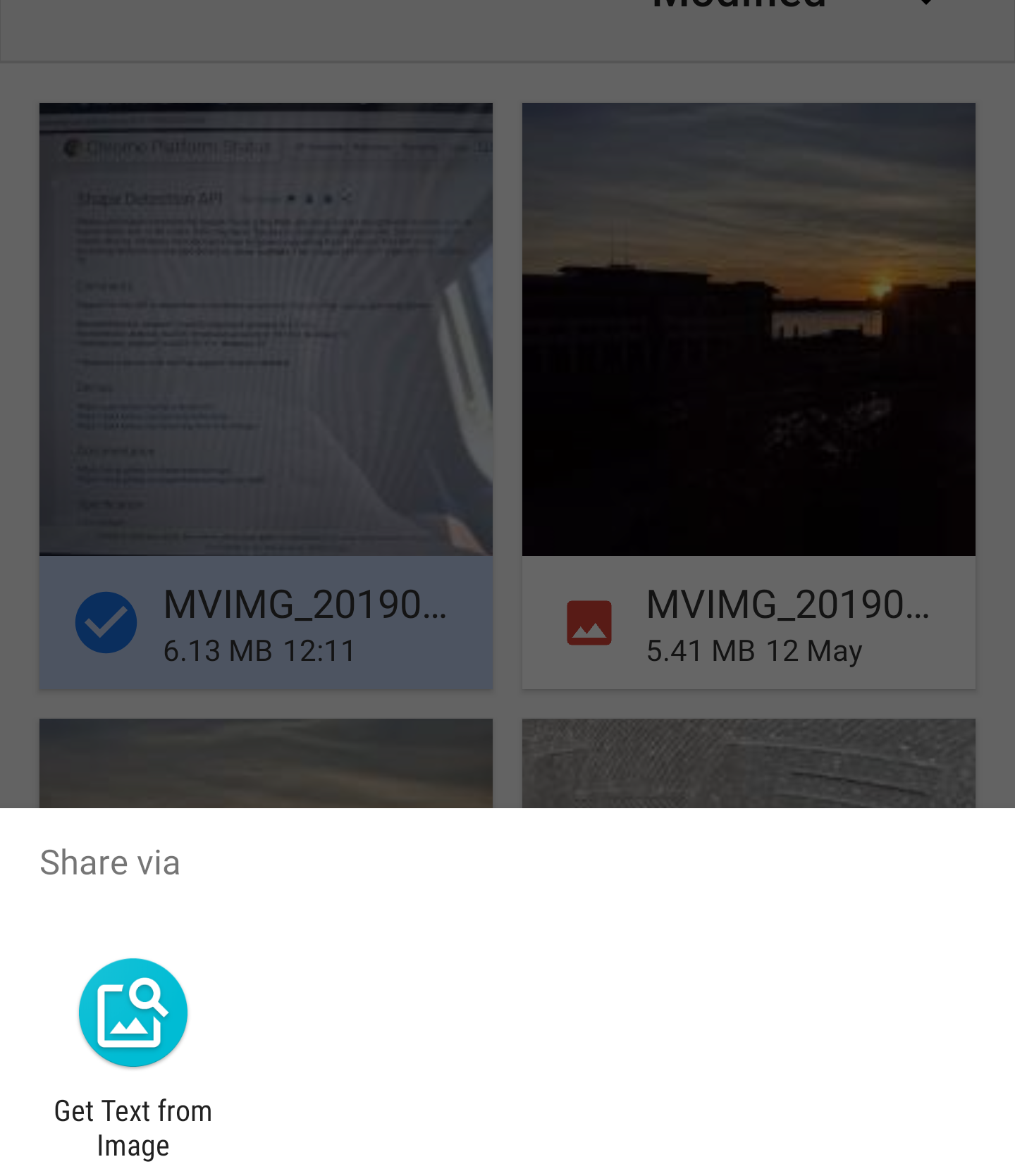
Die Share Target API behandelt das Share Target Dateien wie einen Formularbeitrag. Wenn die Datei für die Web-App freigegeben wird, wird der Service-Worker aktiviert und der fetch Handler mit den fetch aufgerufen. Die Daten befinden sich jetzt im Service Worker, aber ich benötige sie im aktuellen Fenster, damit ich sie verarbeiten kann. Der Service weiß, in welchem Fenster die Anforderung aufgerufen wurde, sodass Sie problemlos auf den Client zugreifen und ihm die Daten senden können.
self.addEventListener('fetch', event => {
if (event.request.method === 'POST') {
event.respondWith(Response.redirect('/index.html'));
event.waitUntil(async function () {
const data = await event.request.formData();
const client = await self.clients.get(event.resultingClientId || event.clientId);
const file = data.get('file');
client.postMessage({ file, action: 'load-image' });
}());
return;
}
...
...
}
Sobald sich das Bild in der Benutzeroberfläche befindet, verarbeite ich es mit der Texterkennungs-API.
navigator.serviceWorker.onmessage = (event) => {
const file = event.data.file;
const imgEl = document.getElementById('img');
const outputEl = document.getElementById('output');
const objUrl = URL.createObjectURL(file);
imgEl.src = objUrl;
imgEl.onload = () => {
const texts = await textDetector.detect(imgEl);
texts.forEach(text => {
const textEl = document.createElement('p');
textEl.textContent = text.rawValue;
outputEl.appendChild(textEl);
});
};
...
};
Das größte Problem ist, dass der Browser das Bild nicht auf natürliche Weise dreht (siehe unten), und für die Formerkennungs-API muss sich der Text in der richtigen Leserichtung befinden.
Ich habe das recht einfach zu verwendende EXIF-Js library , um die Drehung zu erkennen und dann einige grundlegende Canvas-Manipulationen EXIF-Js library , um das Bild neu EXIF-Js library .
EXIF.getData(imgEl, async function() {
// http://sylvana.net/jpegcrop/exif_orientation.html
const orientation = EXIF.getTag(this, 'Orientation');
const [width, height] = (orientation > 4)
? [ imgEl.naturalWidth, imgEl.naturalHeight ]
: [ imgEl.naturalHeight, imgEl.naturalWidth ];
canvas.width = width;
canvas.height = height;
const context = canvas.getContext('2d');
// We have to get the correct orientation for the image
// See also https://stackoverflow.com/questions/20600800/js-client-side-exif-orientation-rotate-and-mirror-jpeg-images
switch(orientation) {
case 2: context.transform(-1, 0, 0, 1, width, 0); break;
case 3: context.transform(-1, 0, 0, -1, width, height); break;
case 4: context.transform(1, 0, 0, -1, 0, height); break;
case 5: context.transform(0, 1, 1, 0, 0, 0); break;
case 6: context.transform(0, 1, -1, 0, height, 0); break;
case 7: context.transform(0, -1, -1, 0, height, width); break;
case 8: context.transform(0, -1, 1, 0, 0, width); break;
}
context.drawImage(imgEl, 0, 0);
}
Und Voila, wenn Sie ein Bild für die App freigeben, wird das Bild gedreht und anschließend analysiert, wobei die Ausgabe des gefundenen Texts zurückgegeben wird.
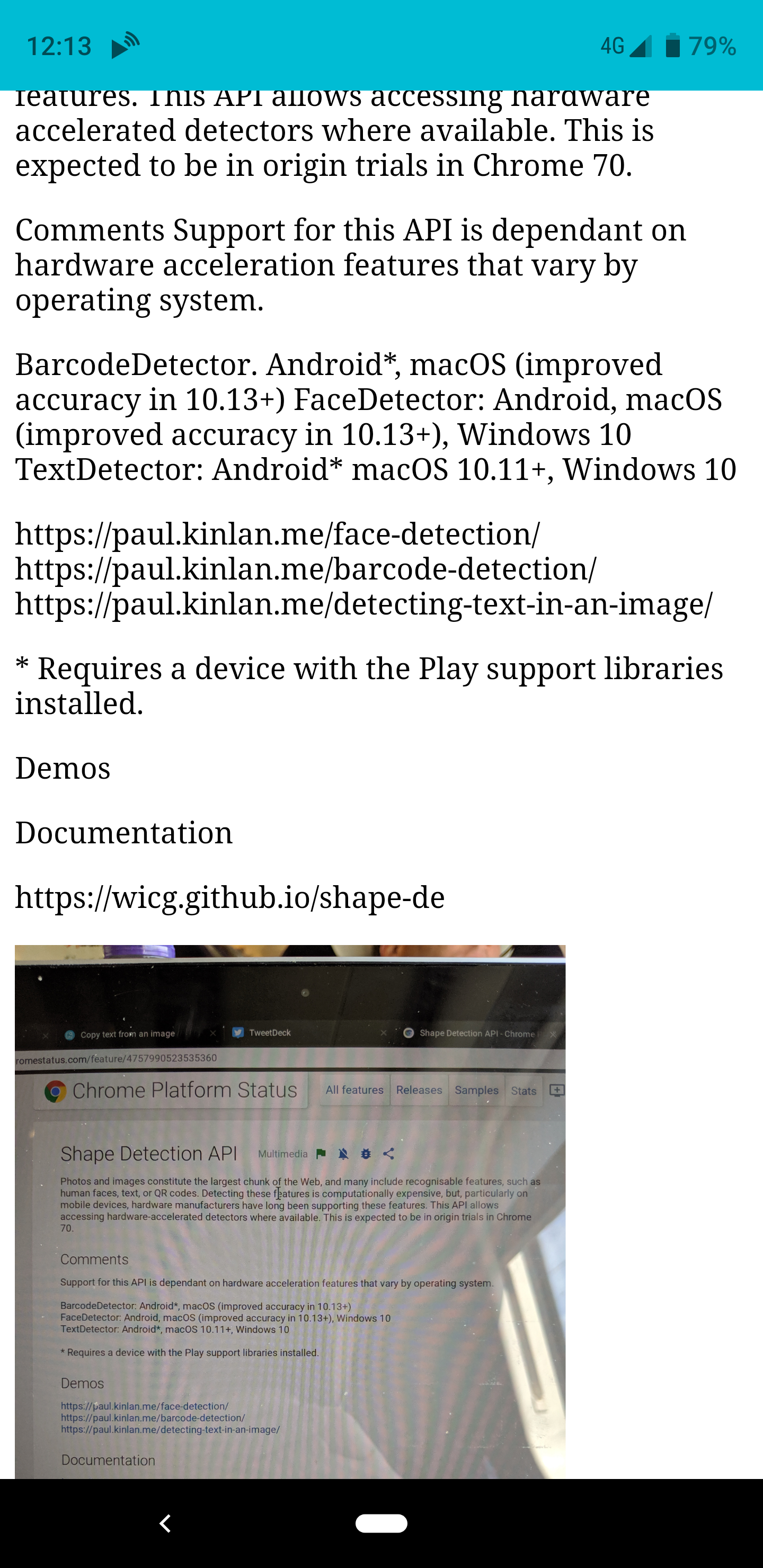
Es hat unglaublich viel Spaß gemacht, dieses kleine Experiment zu erstellen, und es hat mir sofort geholfen. Es wird jedoch das inconsistency of the web platform . Diese APIs sind nicht in allen Browsern verfügbar. Sie sind sogar nicht in allen Chrome-Versionen verfügbar. Das bedeutet, dass ich beim Schreiben dieses Artikels in Chrome OS die App nicht verwenden kann, aber gleichzeitig, wenn ich sie verwenden kann Oh mein Gott, so cool.


Paul Kinlan
Trying to make the web and developers better.




