Ich mag Progressive Web Apps. Ich mag das Modell, das es für den Aufbau guter, solider, zuverlässiger Websites und Apps bietet. Ich mag die API der Hauptplattform - Service Worker -, die es dem PWA-Modell ermöglicht zu arbeiten.
Eine der Fallen, in die wir geraten sind, ist “App Shell”. Das App Shell-Modell besagt, dass Ihre Site eine vollständige Shell Ihrer Anwendung darstellen sollte (damit Sie auch offline etwas erleben können) und Sie dann steuern, wie und wann Sie Inhalte abrufen.
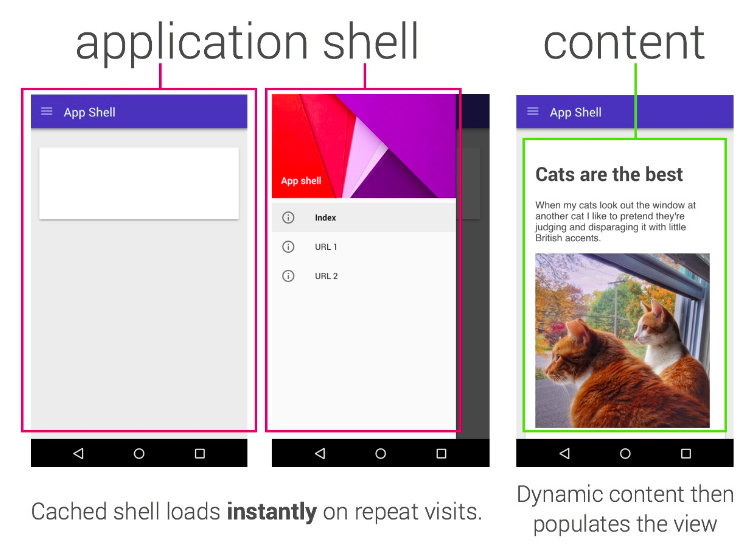
Das App Shell-Modell entspricht in etwa einem “SPA” (Single Page App) & mdash; Sie laden die Shell, dann wird jede nachfolgende Navigation von JS direkt auf Ihrer Seite gehandhabt. Es funktioniert in vielen Fällen gut.
Ich glaube nicht, dass App Shell das einzige oder das beste Modell ist, und wie immer unterscheidet sich Ihre Wahl von Situation zu Situation; Mein eigener Blog verwendet beispielsweise ein einfaches “Stale-While-Revalidate” -Muster, bei dem jede Seite zwischengespeichert wird, während Sie auf der Website navigieren, und Aktualisierungen werden bei einer späteren Aktualisierung angezeigt. In diesem Beitrag möchte ich ein Modell erkunden, mit dem ich kürzlich experimentiert habe.
Zur App Shell oder nicht App Shell
Im klassischen Modell der App Shell ist es fast unmöglich, einen progressiven Rendering zu unterstützen, und ich wollte ein wirklich “progressives” Modell für den Aufbau einer Site mit Service-Mitarbeitern, die folgende Eigenschaften aufwiesen:
- Es funktioniert ohne JS
- Es funktioniert, wenn kein Service Worker unterstützt wird
- Es ist schnell
Ich wollte dies demonstrieren, indem ich ein Projekt aufbaute, das ich schon immer aufbauen wollte: A River of News + TweetDeck Hybrid. Für eine bestimmte Sammlung von RSS-Feeds rendern Sie sie in Spaltenform.
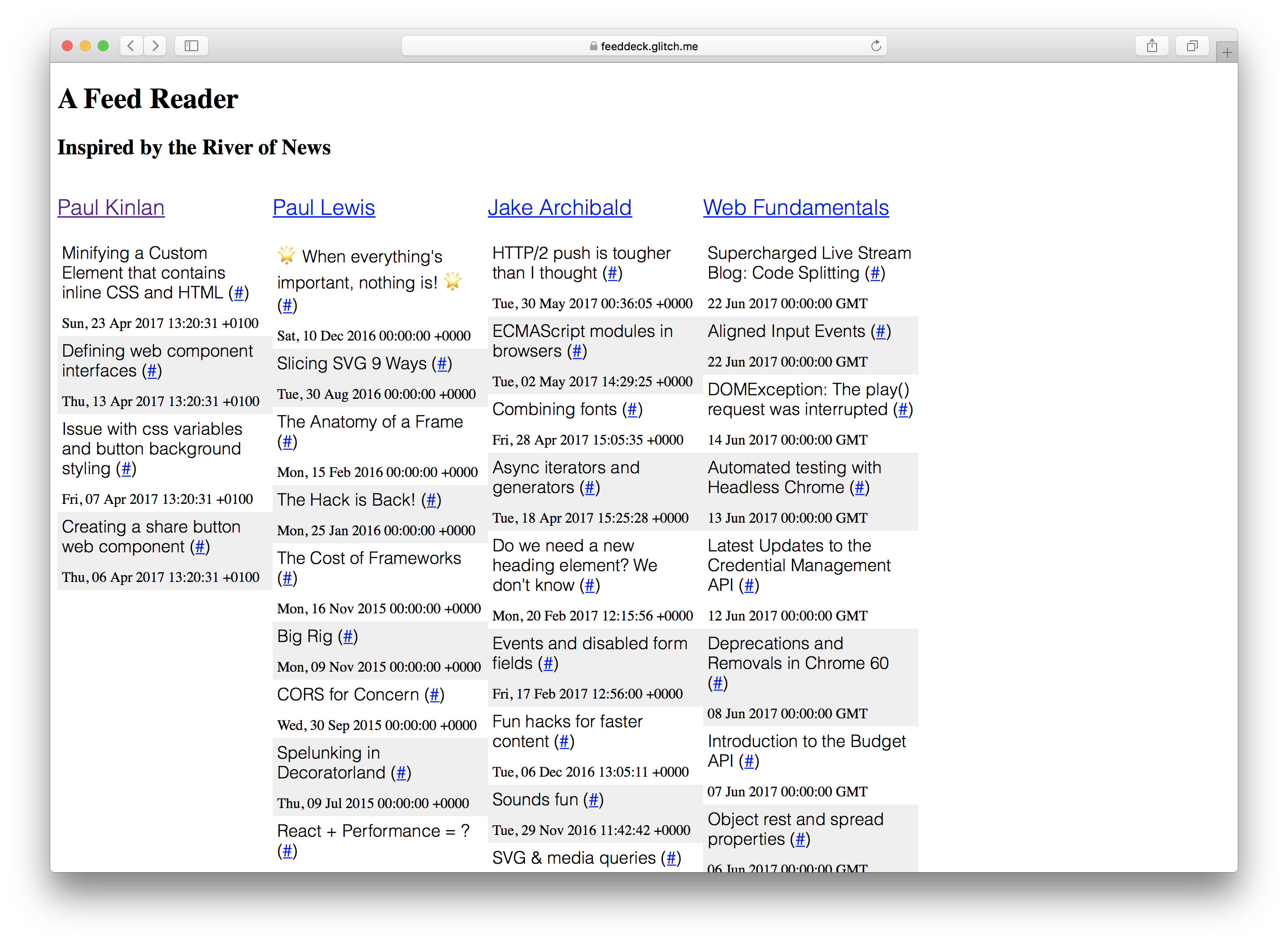
Das “Feed Deck” ist eine gute Referenz für das Experimentieren mit Service Worker und die progressive Verbesserung. Es hat eine vom Server gerenderte Komponente, es benötigt eine “Shell”, um dem Benutzer schnell etwas anzuzeigen, und es hat dynamisch generierten Inhalt, der regelmäßig aktualisiert werden muss. Schließlich, weil es ein persönliches Projekt ist, brauche ich nicht zu viel Serverinfrastruktur, um Benutzerkonfiguration und -authentifizierung zu speichern.
Das meiste habe ich erreicht und ich habe viel gelernt. Einige Dinge erfordern noch JS, aber die Anwendung in der Theorie funktioniert ohne JS; Ich sehne mich danach, dass NodeJS mehr mit DOM APIs gemeinsam hat; Ich habe es komplett mit Glitch auf Chrome OS gebaut, aber dieses letzte Stück ist eine Geschichte für einen anderen Tag.
Ich habe einige Definitionen dafür definiert, was “Works” schon früh im Projekt bedeutet.
- “Es funktioniert ohne JS” & mdash; Der Inhalt wird auf dem Bildschirm angezeigt und es gibt einen klaren Pfad für alles, was ohne JS in der Zukunft funktioniert (oder es gibt eine klare Begründung dafür, warum es nicht aktiviert wurde). Ich kann nicht einfach “nah” sagen.
- “Es funktioniert, wenn es keine Unterstützung für einen Service Worker gibt” & mdash; alles sollte laden, funktionieren und blitzschnell sein, aber ich freue mich, wenn es offline nicht überall funktioniert.
Aber das war nicht die einzige Geschichte, wenn wir JS und Unterstützung für einen Service-Mitarbeiter hatten, hatte ich ein Mandat, um sicherzustellen,
- Es wurde sofort geladen
- Es war zuverlässig und hat vorhersehbare Leistungsmerkmale
- Es funktionierte vollständig offline
Mea culpa: Wenn Sie sich den Code ansehen und ihn in einem älteren Browser ausführen, besteht eine große Chance, dass es nicht funktioniert. Ich habe ES6 gewählt, aber das ist keine unüberwindbare Hürde.
Wenn wir uns darauf konzentrieren sollten, eine Erfahrung zu erstellen, die ohne aktiviertes JavaScript funktioniert, dann sollten wir so viel wie möglich auf dem Server rendern.
Schließlich hatte ich ein sekundäres Ziel: Ich wollte herausfinden, wie machbar es war, Logik zwischen Ihrem Service Worker und Ihrem Server zu teilen. Ich sage eine Lüge, das war die Sache, die mich am meisten und eine Menge Vorteile erregt hat der progressiven Geschichte fiel aus dem Rücken.
Was zuerst kam. Der Server oder der Service Worker?
Es war beides gleichzeitig. Ich muss vom Server rendern, aber weil der Service-Mitarbeiter zwischen dem Browser und dem Netzwerk sitzt, musste ich darüber nachdenken, wie die beiden zusammenspielen.
Ich war in einer glücklichen Lage, da ich nicht viele einzigartige Serverlogik hatte, so dass ich das Problem ganzheitlich und gleichzeitig angehen konnte. Die Prinzipien, die ich befolgte, waren zu überlegen, was ich mit dem ersten Rendern der Seite erreichen wollte (die Erfahrung, die jeder Benutzer bekommen würde) und anschließenden Rendern der Seite (die Erfahrung, die engagierte Benutzer bekommen würden) mit und ohne Servicemitarbeiter.
** Erst rendern ** & mdash; Da kein Service Worker zur Verfügung stand, musste ich sicherstellen, dass der erste Render so viele Seiteninhalte wie möglich enthielt und auf dem Server erzeugte.
Wenn der Benutzer einen Browser hat, der Service-Mitarbeiter unterstützt, kann ich ein paar interessante Dinge tun. Ich habe bereits die Template-Logik auf dem Server erstellt und es gibt nichts Besonderes an ihnen, dann sollten sie die gleichen Vorlagen sein, die ich direkt auf dem Client verwenden würde. Der Service-Mitarbeiter kann die Vorlagen zum `OnInstall’-Zeitpunkt abrufen und sie zur späteren Verwendung speichern.
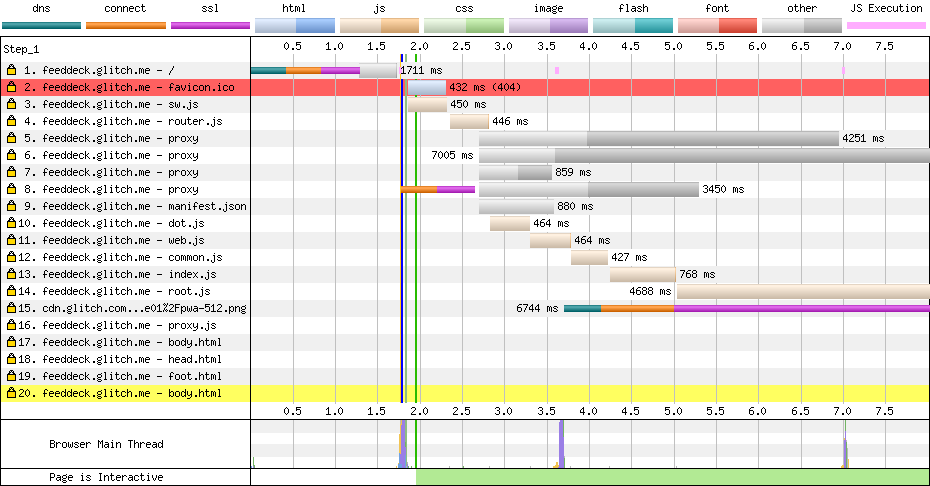
** Zweites Rendern ohne Servicearbeiter ** & mdash; Es sollte genau wie ein erster Renderer funktionieren. Wir könnten von normalem HTTP-Caching profitieren, aber die Theorie ist die gleiche: Machen Sie die Erfahrung schnell.
** Zweites Rendern with service worker ** & mdash; Es sollte * genau * wie ein erster Server rendern, aber alles innerhalb des Service Worker. Ich habe keine traditionelle Schale. Wenn Sie sich das Netzwerk ansehen, sehen Sie nur den vollständig zusammengesetzten HTML: Struktur und Inhalt.

“Der Render” & mdash; Streaming ist unser Freund
Ich habe versucht, so progressiv wie möglich zu sein, was bedeutet, dass ich so viel wie möglich auf dem Server rendern muss. Ich hatte eine Herausforderung, wenn ich alle Daten von allen RSS-Feeds zusammenführen würde, dann würde der erste Render von Netzwerkanfragen an RSS-Feeds blockiert werden und somit würden wir den ersten Rendervorgang verlangsamen.
Ich habe den folgenden Pfad gewählt:
- Render den Kopf der Seite & mdash; Es ist relativ statisch, und dies auf den Bildschirm zu bringen, hilft schnell bei der perceived Leistung.
- Rendere die Struktur der Seite basierend auf der Konfiguration (den Spalten) & mdash; Für einen bestimmten Benutzer ist dies momentan statisch und es ist wichtig für Benutzer, es schnell sichtbar zu machen.
- Rendern Sie die Spaltendaten **, wenn ** wir den Inhalt zwischengespeichert und verfügbar haben, können wir dies sowohl auf dem Server als auch auf dem Service-Mitarbeiter tun
- Rendern Sie die Fußzeile der Seite, die die Logik enthält, um den Inhalt der Seite regelmäßig zu aktualisieren.
Angesichts dieser Einschränkungen muss alles asynchron sein und ich muss alles so schnell wie möglich im Netzwerk finden.
Es gibt einen Mangel an Streaming Templating-Bibliotheken im Internet. Ich habe streaming-dot von meinem guten Freund und Kollegen Surma verwendet, der ein Port des Template-Frameworks doT ist, aber mit zusätzlichen Generatoren, damit er in einen Node oder DOM-Stream schreiben und nicht blockieren kann Der gesamte Inhalt ist verfügbar.
Das Rendern der Spaltendaten (d. H. Was sich in einem Feed befand) ist das wichtigste Stück, und dies erfordert zur Zeit beim ersten Laden JavaScript auf dem Client. Das System ist so eingerichtet, dass alles für den ersten Ladevorgang auf dem Server gerendert werden kann, aber ich habe im Netzwerk nicht blockiert.
Wenn die Daten bereits abgerufen wurden und im Service-Mitarbeiter verfügbar sind, können wir dies schnell an den Benutzer weitergeben, auch wenn es schnell veralten kann.
Der Code zum Rendern des Inhalts, während er aysnc ist, ist relativ prozedural und folgt dem zuvor beschriebenen Modell: Wir rendern den Header zum Stream, wenn das Template fertig ist, und rendern dann den Body-Inhalt in den Stream, der seinerseits auf Inhalt warten kann verfügbar wird auch in den Stream geleert und schließlich, wenn alles fertig ist, fügen wir in der Fußzeile hinzu und flush das zum Antwortstream.
Unten ist der Code, den ich auf dem Server und dem Service-Mitarbeiter verwende.
const root = (dataPath, assetPath) => {
let columnData = loadData(`${dataPath}columns.json`).then(r => r.json());
let headTemplate = getCompiledTemplate(`${assetPath}templates/head.html`);
let bodyTemplate = getCompiledTemplate(`${assetPath}templates/body.html`);
let itemTemplate = getCompiledTemplate(`${assetPath}templates/item.html`);
let jsonFeedData = fetchCachedFeedData(columnData, itemTemplate);
/*
* Render the head from the cache or network
* Render the body.
* Body has template that brings in config to work out what to render
* If we have data cached let's bring that in.
* Render the footer - contains JS to data bind client request.
*/
const headStream = headTemplate.then(render => render({ columns: columnData }));
const bodyStream = jsonFeedData.then(columns => bodyTemplate.then(render => render({ columns: columns })));
const footStream = loadTemplate(`${assetPath}templates/foot.html`);
let concatStream = new ConcatStream;
headStream.then(stream => stream.pipeTo(concatStream.writable, { preventClose:true }))
.then(() => bodyStream)
.then(stream => stream.pipeTo(concatStream.writable, { preventClose: true }))
.then(() => footStream)
.then(stream => stream.pipeTo(concatStream.writable));
return Promise.resolve(new Response(concatStream.readable, { status: "200" }))
}
Mit diesem Modell war es relativ einfach, den obigen Code zu erhalten und auf dem Server * und * im Service-Mitarbeiter zu arbeiten.
Unified Logic Server und Service Worker Logik & mdash; Reifen und Hürden
Es war sicherlich nicht leicht, zu einer gemeinsamen Codebasis zwischen Server und Client zu gelangen, das Node + NPM Ökosystem und das Web JS Ökosystem sind wie genetisch identische Zwillinge, die mit verschiedenen Familien aufgewachsen sind und wenn sie sich schließlich treffen, gibt es viele Gemeinsamkeiten und viele Unterschiede, die überwunden werden müssen … Es klingt wie eine großartige Idee für einen Film.
Ich entschied mich dafür, Web über das Projekt hinweg zu bevorzugen. Ich habe mich dazu entschieden, weil ich den Code nicht in den Browser des Benutzers einbinden und laden möchte, sondern diesen Treffer auf dem Server nehmen kann (ich kann das skalieren, der Benutzer kann das nicht), also wenn die API nicht vorhanden war. Wenn ich in Node unterstützt werde, müsste ich ein kompatibles Shim finden.
Hier sind einige der Herausforderungen, denen ich gegenüberstand.
Ein defektes Modulsystem
Als sowohl das Node- als auch das Web Ecosystem aufwuchsen, entwickelten sie beide verschiedene Möglichkeiten, Code zur Designzeit zu kompo- nieren, zu segmentieren und zu importieren. Das war ein echtes Problem, als ich versuchte, dieses Projekt aufzubauen.
Ich wollte CommonJS nicht im Browser haben. Ich habe den irrationalen Wunsch, von so viel Werkzeugbau wie möglich wegzubleiben und zu meiner Verachtung hinzuzufügen, wie Bündelung funktioniert, es hat mir nicht viele Optionen gelassen.
Meine Lösung im Browser war die flache Methode ‘importScripts’. Sie funktioniert, aber sie hängt von einer sehr spezifischen Dateireihenfolge ab, wie es im Service-Mitarbeiter so aussieht:
** sw.js **
importScripts(`/scripts/router.js`);
importScripts(`/scripts/dot.js`);
importScripts(`/scripts/platform/web.js`);
importScripts(`/scripts/platform/common.js`);
importScripts(`/scripts/routes/index.js`);
importScripts(`/scripts/routes/root.js`);
importScripts(`/scripts/routes/proxy.js`);
Und dann habe ich für den Knoten den normalen CommonJS-Lademechanismus in der gleichen Datei verwendet, aber sie werden hinter einer einfachen “if” -Anweisung gegattert, um die Module zu importieren.
if (typeof module !== 'undefined' && module.exports) {
var doT = require('../dot.js');
...
Meine Lösung ist keine skalierbare Lösung, es funktionierte aber auch mit Code, den ich nicht wollte.
Ich freue mich auf den Tag, an dem Node Module unterstützt, die die Browser unterstützen … Wir brauchen etwas Einfaches, Vernünftiges, Gemeinsames und Skalierbares.
Wenn Sie den Code auschecken, sehen Sie, dass dieses Muster in fast jeder freigegebenen Datei verwendet wird, und in vielen Fällen wurde es benötigt, da ich die WHATWG-Stream-Referenzimplementierung importieren musste.
Gekreuzte Streams
Streams sind wahrscheinlich das wichtigste Primitiv, das wir im Computing haben (und wahrscheinlich das am wenigsten verstandene), und sowohl Node als auch das Web haben ihre eigenen völlig unterschiedlichen Lösungen. Es war ein Alptraum, mit diesem Projekt fertig zu werden und wir müssen wirklich eine einheitliche Lösung (idealerweise DOM Streams) standardisieren.
Zum Glück gibt es eine vollständige Implementierung der Streams API, die Sie in Node einbinden können, und Sie müssen lediglich ein paar Dienstprogramme schreiben, um aus Web Stream -> Knoten-Stream und Knoten-Stream -> Web zu mappen Strom.
const nodeReadStreamToWHATWGReadableStream = (stream) => {
return new ReadableStream({
start(controller) {
stream.on('data', data => {
controller.enqueue(data)
});
stream.on('error', (error) => controller.abort(error))
stream.on('end', () => {
controller.close();
})
}
});
};
class FromWHATWGReadableStream extends Readable {
constructor(options, whatwgStream) {
super(options);
const streamReader = whatwgStream.getReader();
pump(this);
function pump(outStream) {
return streamReader.read().then(({ value, done }) => {
if (done) {
outStream.push(null);
return;
}
outStream.push(value.toString());
return pump(outStream);
});
}
}
}
Diese beiden Hilfsfunktionen wurden nur auf der Node-Seite dieses Projekts verwendet und sie wurden verwendet, um Daten in Node-APIs zu importieren, die WHATWG-Streams nicht akzeptieren konnten, und ebenfalls Daten an WHATWG Stream-kompatible APIs zu übergeben, die Node-Streams nicht verstanden . Ich benötigte dies speziell für die “Fetch” API in Node.
Sobald ich Streams sortiert hatte, war das letzte Problem und die Inkonsistenz Routing (zufälligerweise brauchte ich die Stream Utils am meisten).
Shared Routing
Das Node-Ökosystem, insbesondere Express, ist unglaublich bekannt und erstaunlich robust, aber wir haben kein gemeinsames Modell zwischen Client und Service-Mitarbeiter.
Vor Jahren schrieb ich LeviRoutes, eine einfache Browser-Seitenbibliothek, die ExpressJS wie Routen behandelte und in die History-API und auch die “onhashchange” -API eingebunden wurde. Niemand hat es benutzt, aber ich war glücklich. Ich schaffte es, die Spinnweben zu stauben (mach ein oder zwei Tweaks) und stelle sie in dieser Anwendung bereit. Mit Blick auf den Code unten sehen Sie, dass mein Routing nearly das gleiche ist.
** server.js **
app.get('/', (req, res, next) => {
routes['root'](dataPath, assetPath)
.then(response => node.responseToExpressStream(res, response));
});
app.get('/proxy', (req, res, next) => {
routes['proxy'](dataPath, assetPath, req)
.then(response => response.body.pipe(res, {end: true}));
})
** sw.js **
// The proxy server '/proxy'
router.get(`${self.location.origin}/proxy`, (e) => {
e.respondWith(routes['proxy'](dataPath, assetPath, e.request));
}, {urlMatchProperty: 'href'});
// The root '/'
router.get(`${self.location.origin}/$`, (e) => {
e.respondWith(routes['root'](dataPath, assetPath));
}, {urlMatchProperty: 'href'});
Ich würde love sehen, um eine einheitliche Lösung zu sehen, die das Service-Arbeiter onfetch API in Knoten bringt.
Ich würde auch ein “Express” -ähnliches Framework sehen, das Knoten- und Browser-Code-Request-Routing vereinheitlicht. Es gab gerade genug Unterschiede, dass ich nicht überall die gleiche Quelle haben konnte. Wir können Routen auf dem Client und dem Server fast genau gleich handhaben, also sind wir nicht weit entfernt.
Kein DOM außerhalb des Renderings
Wenn dem Benutzer kein Service-Mitarbeiter zur Verfügung steht, ist die Logik für die Site recht traditionell. Wir rendern die Site auf dem Server und aktualisieren dann den Inhalt der Seite inkrementell durch eine herkömmliche AJAX-Abfrage.
Die Logik verwendet die DOMParser-API, um einen RSS-Feed in etwas umzuwandeln, das ich auf der Seite filtern und abfragen kann.
// Get the RSS feed data.
fetch(`/proxy?url=${feedUrl}`)
.then(feedResponse => feedResponse.text())
// Convert it in to DOM
.then(feedText => {
const parser = new DOMParser();
return parser.parseFromString(feedText,'application/xml');
})
// Find all the news items
.then(doc => doc.querySelectorAll('item'))
// Convert to an array
.then(items => Array.prototype.map.call(items, item => convertRSSItemToJSON(item)))
// Don't add in items that already exist in the page
.then(items => items.filter(item => !!!(document.getElementById(item.guid))))
// DOM Template.
.then(items => items.map(item => applyTemplate(itemTemplate.cloneNode(true), item)))
// Add it into the page
.then(items => items.forEach(item => column.appendChild(item)))
Der Zugriff auf das DOM des RSS-Feeds mithilfe der Standard-APIs im Browser war unglaublich nützlich und ermöglichte es mir, meinen eigenen Template-Mechanismus (auf den ich ziemlich stolz bin) zu verwenden, um die Seite dynamisch zu aktualisieren.
<template id='itemTemplate'>
<div class="item" data-bind_id='guid'>
<h3><span data-bind_inner-text='title'></span> (<a data-bind_href='link'>#</a>)</h3>
<div data-bind_inner-text='pubDate'></div>
</div>
</template>
<script>
const applyTemplate = (templateElement, data) => {
const element = templateElement.content.cloneNode(true);
const treeWalker = document.createTreeWalker(element, NodeFilter.SHOW_ELEMENT, () => NodeFilter.FILTER_ACCEPT);
while(treeWalker.nextNode()) {
const node = treeWalker.currentNode;
for(let bindAttr in node.dataset) {
let isBindableAttr = (bindAttr.indexOf('bind_') == 0) ? true : false;
if(isBindableAttr) {
let dataKey = node.dataset[bindAttr];
let bindKey = bindAttr.substr(5);
node[bindKey] = data[dataKey];
}
}
}
return element;
};
</script>Ich war sehr zufrieden mit mir selbst, bis ich merkte, dass ich nichts davon auf dem Server oder in einem Service-Arbeiter verwenden konnte. Die einzige Lösung, die ich hatte, war, einen benutzerdefinierten XML-Parser einzubringen und das zu generieren, um das HTML zu erzeugen. Es fügte einige Komplikationen hinzu und ließ mich das Netz fluchen.
Auf lange Sicht würde ich gerne sehen, dass einige der DOM-APIs zu den Arbeitern gebracht und auch in Node unterstützt werden, aber die Lösung, die ich habe funktioniert, auch wenn es nicht optimal ist.
Ist es möglich?
Es gibt wirklich zwei Fragen in diesem Post:
- Ist es praktisch, Systeme zu erstellen, die sich einen gemeinsamen Server und Service-Mitarbeiter teilen?
- Ist es möglich, eine vollständig progressive Progressive Web App zu erstellen?
Ist es praktisch, Systeme zu erstellen, die einen gemeinsamen Server und Service-Mitarbeiter teilen?
Es ist möglich, Systeme zu erstellen, die sich einen gemeinsamen Server und Service-Mitarbeiter teilen, aber ist es praktisch? Ich mag die Idee, aber ich denke, dass es mehr Forschung benötigt, denn wenn Sie JS den ganzen Weg gehen, dann gibt es eine Menge Probleme zwischen der Node und Web-Plattform, die ausgebügelt werden müssen.
Persönlich würde ich gerne mehr “Web” APIs im Knoten-Ökosystem sehen.
Ist es möglich eine progressive Progressive Web App zu erstellen?
Ja.
Ich bin sehr froh, dass ich das getan habe. Auch wenn Sie nicht die gleiche Sprache auf dem Client wie auf dem Dienst teilen, gibt es eine Reihe von kritischen Dingen, die ich zu zeigen vermochte.
- AppShell ist nicht das einzige Modell, dem Sie folgen können, der wichtige Punkt ist, dass der Service-Mitarbeiter you die Kontrolle über das Netzwerk erhält und you entscheiden kann, was für Ihren Anwendungsfall am besten ist. 2. Es ist möglich, eine progressiv wiedergegebene Erfahrung zu erstellen, die Service-Mitarbeiter verwendet, um Leistung und Ausfallsicherheit (sowie ein installiertes Gefühl, wenn Sie möchten) zu bringen. Sie müssen ganzheitlich denken, Sie müssen zunächst so viel wie möglich auf dem Server rendern und dann die Kontrolle im Client übernehmen. 3. Es ist möglich, über Erfahrungen nachzudenken, die “trisomorph” (ich glaube immer noch, der Begriff isomorph ist am besten) mit einer gemeinsamen Code-Basis, einer gemeinsamen Routing-Struktur und einer gemeinsamen Logik zwischen Client, Service-Mitarbeiter und Server erstellt wird.
Ich überlege dies als letzten Gedanken: Wir müssen mehr darüber nachdenken, wie wir progressive Web-Apps erstellen wollen, und wir müssen die Muster, die uns dorthin bringen, weiter vorantreiben. AppShell war ein großartiger Start, es ist nicht das Ende. Progressive Rendering und Verbesserung sind der Schlüssel zum langfristigen Erfolg des Internets, kein anderes Medium kann dies so gut wie das Web.
Wenn Sie sich für den Code interessieren, es auf Github überprüfen, aber Sie können auch damit spielen direkt und Remix es auf Glitch


Paul Kinlan
Trying to make the web and developers better.




