Tuve un poco de tiempo de inactividad después de Google IO y quise rascarme una picazón a largo plazo que he tenido. Solo quiero poder copiar el texto que se encuentra dentro de las imágenes en el navegador. Eso es todo. Creo que sería una buena característica para todos.
No es fácil agregar funcionalidad directamente a Chrome, pero sé que puedo aprovechar el sistema de intención en Android y ahora puedo hacerlo con la Web (o al menos Chrome en Android).
Dos nuevas adiciones a la plataforma web: Share Target Level 2 (o como me gusta llamarlo File Share) y TextDetector en la API de detección de formas - have allowed me to build a utility that I can Share images to and get the text held inside them .
La implementación básica es relativamente directa, crea un objetivo compartido y un manejador en el trabajador de servicio, y luego, una vez que tiene la imagen que el usuario ha compartido, ejecuta TextDetector en ella.
Share Target API permite que su aplicación web sea parte del subsistema de uso compartido nativo, y en este caso, ahora puede registrarse para manejar todos los tipos de image/* declarándolo dentro de Web App Manifest siguiente manera.
"share_target": {
"action": "/index.html",
"method": "POST",
"enctype": "multipart/form-data",
"params": {
"files": [
{
"name": "file",
"accept": ["image/*"]
}
]
}
}
Cuando su PWA esté instalado, lo verá en todos los lugares desde donde comparte imágenes de la siguiente manera:
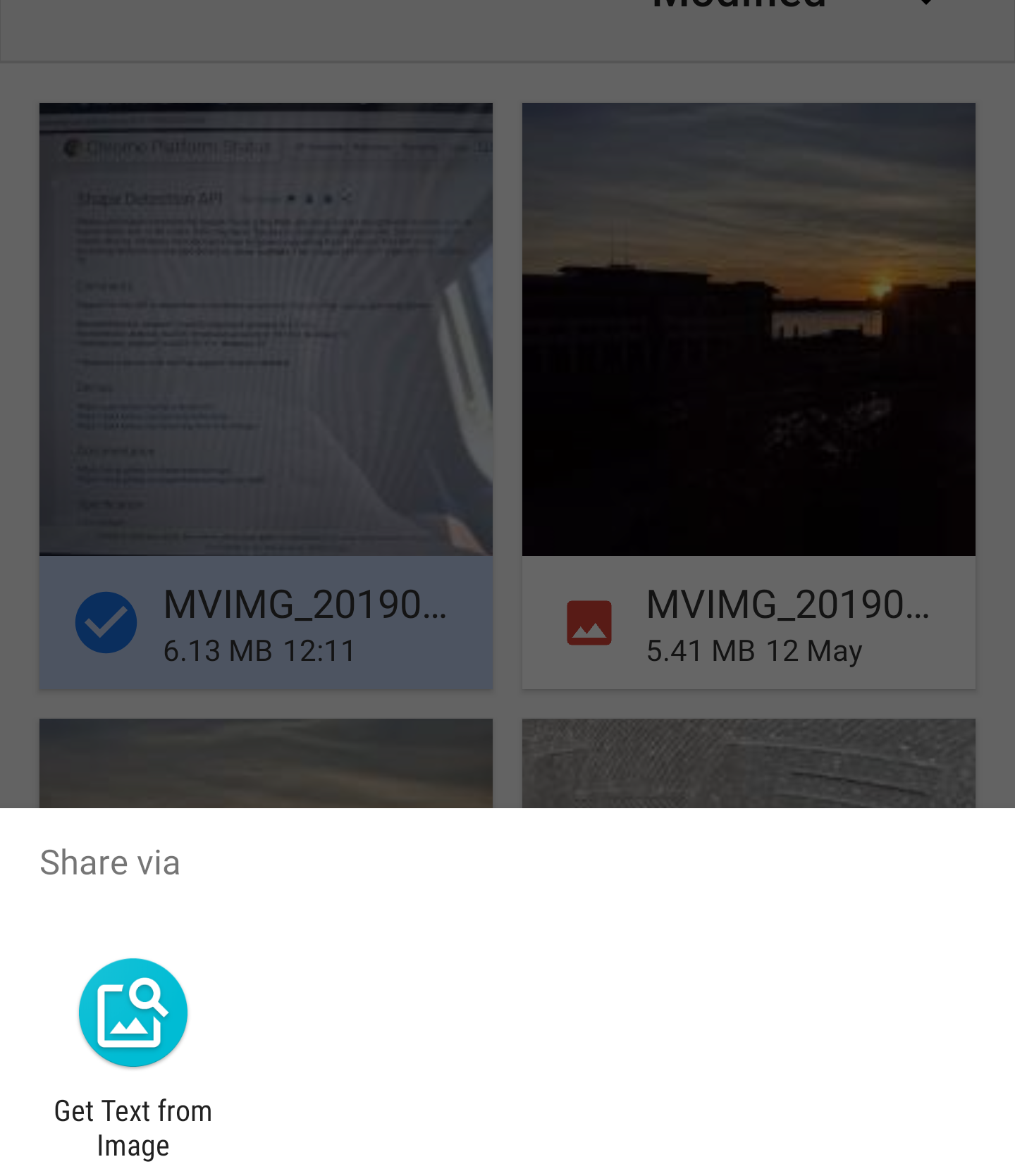
La API Share Target trata el intercambio de archivos como una publicación de formulario. Cuando el archivo se comparte con la aplicación web, el trabajador del servicio se activa, el controlador fetch se invoca con los datos del archivo. Los datos ahora están dentro del Trabajador de servicios, pero los necesito en la ventana actual para poder procesarlos, el servicio sabe qué ventana invocó la solicitud, para que pueda dirigirse fácilmente al cliente y enviarle los datos.
self.addEventListener('fetch', event => {
if (event.request.method === 'POST') {
event.respondWith(Response.redirect('/index.html'));
event.waitUntil(async function () {
const data = await event.request.formData();
const client = await self.clients.get(event.resultingClientId || event.clientId);
const file = data.get('file');
client.postMessage({ file, action: 'load-image' });
}());
return;
}
...
...
}
Una vez que la imagen está en la interfaz de usuario, la proceso con la API de detección de texto.
navigator.serviceWorker.onmessage = (event) => {
const file = event.data.file;
const imgEl = document.getElementById('img');
const outputEl = document.getElementById('output');
const objUrl = URL.createObjectURL(file);
imgEl.src = objUrl;
imgEl.onload = () => {
const texts = await textDetector.detect(imgEl);
texts.forEach(text => {
const textEl = document.createElement('p');
textEl.textContent = text.rawValue;
outputEl.appendChild(textEl);
});
};
...
};
El mayor problema es que el navegador no rota naturalmente la imagen (como se puede ver a continuación), y la API de detección de formas necesita que el texto esté en la orientación de lectura correcta.
Utilicé EXIF-Js library bastante fácil de usar, para detectar la rotación y luego realizar una manipulación básica del lienzo para reorientar la imagen.
EXIF.getData(imgEl, async function() {
// http://sylvana.net/jpegcrop/exif_orientation.html
const orientation = EXIF.getTag(this, 'Orientation');
const [width, height] = (orientation > 4)
? [ imgEl.naturalWidth, imgEl.naturalHeight ]
: [ imgEl.naturalHeight, imgEl.naturalWidth ];
canvas.width = width;
canvas.height = height;
const context = canvas.getContext('2d');
// We have to get the correct orientation for the image
// See also https://stackoverflow.com/questions/20600800/js-client-side-exif-orientation-rotate-and-mirror-jpeg-images
switch(orientation) {
case 2: context.transform(-1, 0, 0, 1, width, 0); break;
case 3: context.transform(-1, 0, 0, -1, width, height); break;
case 4: context.transform(1, 0, 0, -1, 0, height); break;
case 5: context.transform(0, 1, 1, 0, 0, 0); break;
case 6: context.transform(0, 1, -1, 0, height, 0); break;
case 7: context.transform(0, -1, -1, 0, height, width); break;
case 8: context.transform(0, -1, 1, 0, 0, width); break;
}
context.drawImage(imgEl, 0, 0);
}
Y voila, si comparte una imagen con la aplicación, la girará y luego la analizará devolviendo la salida del texto que ha encontrado.
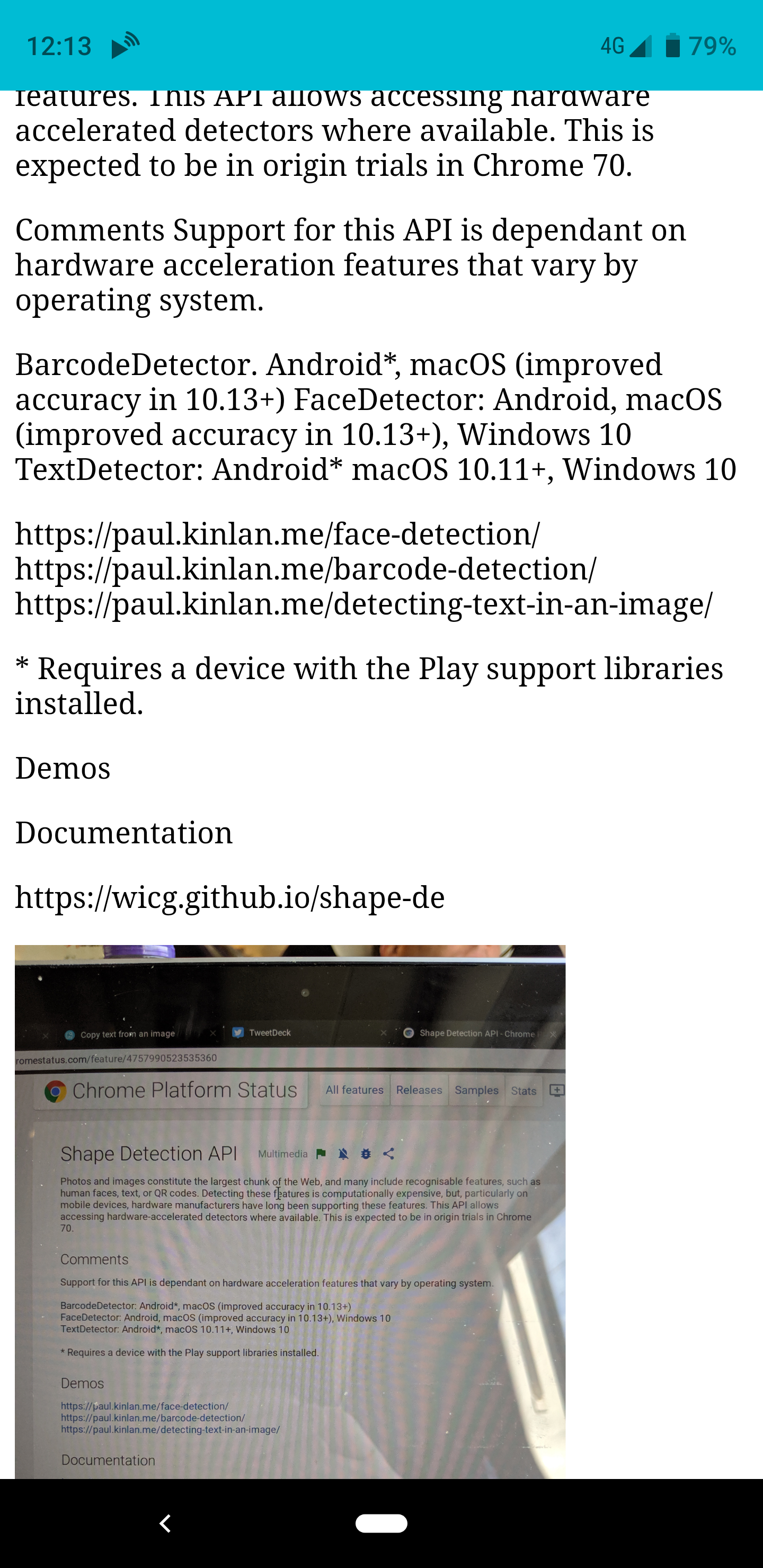
Fue increíblemente divertido crear este pequeño experimento, y ha sido inmediatamente útil para mí. Sin embargo, sí resalta las inconsistency of the web platform . Estas API no están disponibles en todos los navegadores, ni siquiera están disponibles en todas las versiones de Chrome. Esto significa que mientras escribo este artículo sobre Chrome OS, no puedo usar la aplicación, pero al mismo tiempo, cuando puedo usarla. … Dios mío, tan genial.


Paul Kinlan
Trying to make the web and developers better.




