Me gusta Progressive Web Apps. Me gusta el modelo que ofrece para la creación de sitios web y aplicaciones buenos, sólidos y confiables. Me gusta la plataforma API principal, trabajador de servicios, que permite que el modelo PWA funcione.
Una de las trampas en las que hemos caído es “App Shell”. El modelo de App Shell dice que su sitio debe presentar un shell completo de su aplicación (para que la experiencia sea algo incluso cuando esté desconectado) y luego controlar cómo y cuándo extraer el contenido.
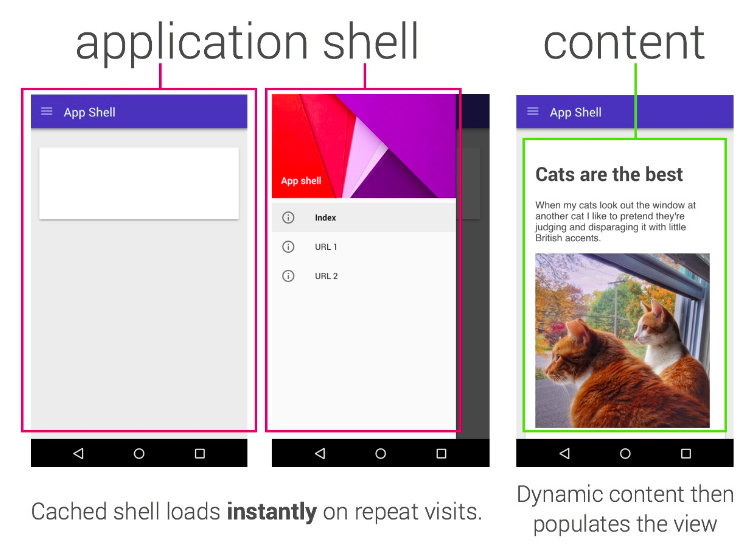
El modelo de App Shell es análogamente similar a un “SPA” (aplicación de una sola página) & mdash; carga el shell, entonces cada navegación subsiguiente es manejada por JS directamente en su página. Funciona bien en muchos casos.
No creo que App Shell sea el * único * ni el mejor modelo, y como siempre, su elección varía de una situación a otra; mi propio blog, por ejemplo, usa un patrón simple “Stale-While-Revalidate” (“A prueba mientras revalida”), cada página se almacena en caché mientras navega por el sitio y las actualizaciones se mostrarán en una actualización posterior; en este post me gustaría explorar un modelo con el que he experimentado recientemente.
Para App Shell o no App Shell
En el modelo clásico de App Shell es casi imposible admitir un render progresivo y quería lograr un modelo verdaderamente “progresivo” para construir un sitio con un trabajador de servicio que tuviera las siguientes propiedades:
- Funciona sin JS
- Funciona cuando no hay soporte para un trabajador de servicio
- Es rápido
Me propuse demostrar esto creando un proyecto que siempre he querido construir: Un río de noticias + TweetDeck híbrido. Para una colección determinada de fuentes RSS, renderícelas en forma de columna.
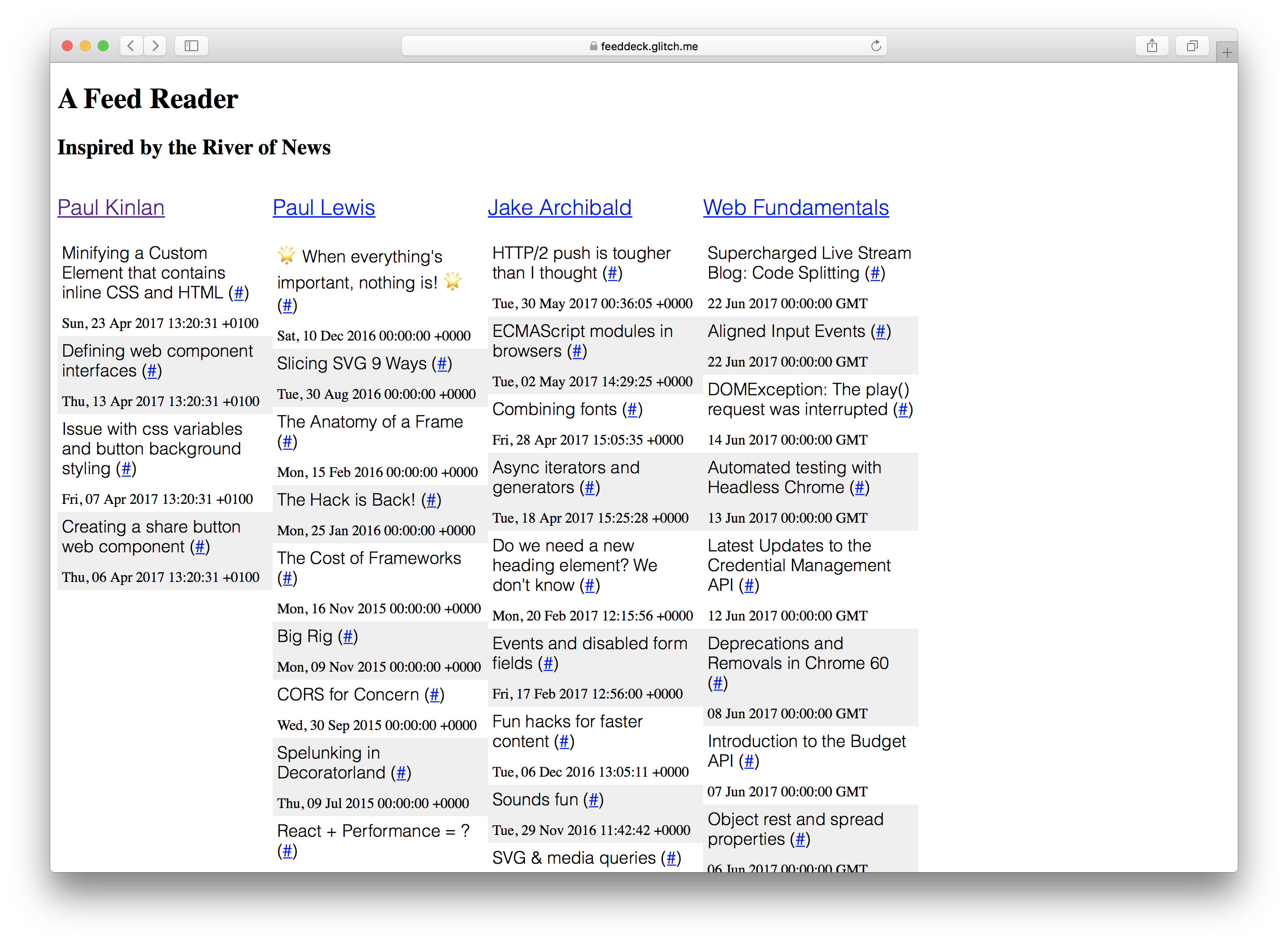
El “Feed Deck” es una buena experiencia de referencia para experimentar con Service Worker y mejorar progresivamente. Tiene un componente de servidor procesado, tiene la necesidad de un “shell” para mostrarle algo al usuario rápidamente y tiene contenido generado dinámicamente que necesita actualizarse regularmente. Finalmente, como es un proyecto personal, no necesito demasiada infraestructura de servidor para guardar la configuración y autenticación del usuario.
Logré la mayor parte de esto y aprendí mucho durante el proceso. Algunas cosas aún requieren JS, pero la aplicación en teoría funciona sin JS; Anhelo que NodeJS tenga más en común con las API DOM; Lo construí completamente en Chrome OS con Glitch pero esta pieza final es una historia para otro día.
Establecí algunas definiciones de lo que “funciona” significa desde el principio del proyecto.
- “Funciona sin JS” & mdash; cargas de contenido en la pantalla y hay una ruta clara para todo lo que funcione sin JS en el futuro (o hay una justificación clara de por qué no estaba habilitado). No puedo simplemente decir “nah”.
- “Funciona cuando no hay soporte para un trabajador de servicio” & mdash; todo debería cargarse, funcionar y ser increíblemente rápido, pero estoy contento si no funciona sin conexión en todas partes.
Pero esa no era la única historia, si teníamos JS y apoyo para un trabajador de servicios, tenía el mandato de garantizar:
- Se cargó al instante
- Fue confiable y tiene características de rendimiento predecibles
- Funcionó completamente sin conexión
Mea culpa: Si miras el código y lo ejecutas en un navegador más antiguo, hay grandes posibilidades de que no funcione, decidí usar ES6, sin embargo, este no es un obstáculo insuperable.
Si tuviéramos que centrarnos en construir una experiencia que funcionara sin JavaScript habilitado, entonces mantendría que debemos rendir tanto como sea posible en el servidor.
Finalmente, tenía un objetivo secundario: quería explorar qué tan factible era compartir la lógica entre su servidor de servicio y su servidor … Digo una mentira, esto fue lo que más me entusiasmó y muchos de los beneficios de la historia progresiva cayó de la parte posterior de esto.
Lo que vino primero. El servidor o el trabajador de servicio?
Fue al mismo tiempo. Tengo que renderizar desde el servidor, pero debido a que el trabajador del servicio se encuentra entre el navegador y la red, tuve que pensar en cómo se relacionaron los dos.
Estaba en una posición afortunada porque no tenía mucha lógica de servidor única, así que podía abordar el problema de manera integral y a la vez. Los principios que seguí fueron pensar en lo que quería lograr con el primer render de la página (la experiencia que obtendría cada usuario) y los renders posteriores de la página (la experiencia que obtendrían los usuarios comprometidos) con y sin un trabajador del servicio.
** Primer render ** y mdash; no habría ningún trabajador de servicio disponible, así que necesitaba asegurarme de que la primera representación contenía tanto contenido de la página como fuera posible y que se generara en el servidor.
Si el usuario tiene un navegador que admita el servicio técnico, entonces puedo hacer un par de cosas interesantes. Ya tengo la lógica de plantilla creada en el servidor y no hay nada especial sobre ellos, entonces deberían ser exactamente las mismas plantillas que usaría directamente en el cliente. El trabajador del servicio puede buscar las plantillas en el momento oninstall y almacenarlas para usarlas en el futuro.
** Segundo render sin trabajador de servicio ** & mdash; Debería actuar exactamente como un primer render. Podríamos beneficiarnos del almacenamiento en caché HTTP normal, pero la teoría es la misma: renderizar la experiencia rápidamente.
** Segundo procesamiento con trabajador de servicio ** & mdash; Debería actuar * exactamente * como un primer servidor renderizado, pero, todo dentro del trabajador del servicio. No tengo el caparazón tradicional. Si miras a la red, todo lo que ves es el HTML totalmente estructurado: estructura y contenido.

“El render” & mdash; Streaming es nuestro amigo
Intentaba ser lo más progresivo posible, lo que significa que necesito renderizar lo más rápido posible en el servidor. Tuve un desafío, si fusionaba todos los datos de todas las fuentes RSS, la primera renderización sería bloqueada por solicitudes de red a feeds RSS y, por lo tanto, ralentizaríamos la primera renderización.
Elegí la siguiente ruta:
- Renderiza el encabezado de la página & mdash; es relativamente estático y consigue esto rápidamente en la pantalla con el rendimiento percibido.
- Renderice la estructura de la página según la configuración (las columnas) & mdash; para un usuario dado, esto es actualmente estático y hacer que sea visible rápidamente es importante para los usuarios.
- Renderizar los datos de la columna ** si ** tenemos el contenido en caché y disponible, podemos hacerlo tanto en el servidor como en el trabajador del servicio
- Renderice el pie de página de la página que contiene la lógica para actualizar dinámicamente el contenido de la página periódicamente.
Teniendo en cuenta estas restricciones, todo debe ser asincrónico y necesito que todo salga a la red lo más rápido posible.
Hay una escasez real de bibliotecas de plantillas de transmisión en la web. Utilicé streaming-dot por mi buen amigo y colega Surma, que es un puerto del framework de plantillas doT pero con generadores añadidos para que pueda escribir en un Node o DOM Stream y no bloquear en todo el contenido está disponible.
Presentar los datos de la columna (es decir, lo que estaba en un feed) es la pieza más importante y, por el momento, requiere JavaScript en el cliente para la primera carga. El sistema está configurado para poder representar todo en el servidor para la primera carga, pero elegí no bloquear en la red.
Si los datos ya se han obtenido y están disponibles en el trabajador del servicio, podemos comunicarlo al usuario rápidamente, incluso si puede volverse obsoleto rápidamente.
El código para representar el contenido mientras se está sincronizado es relativamente de procedimiento y sigue el modelo descrito anteriormente: renderizamos el encabezado en la secuencia cuando la plantilla está lista, luego procesamos el contenido del cuerpo en la secuencia, que a su vez puede estar esperando contenido que cuando disponible también se descargará a la transmisión y, finalmente, cuando todo esté listo, agregaremos el pie de página y lo enviaremos al flujo de respuesta.
A continuación se muestra el código que utilizo en el servidor y el trabajador del servicio.
const root = (dataPath, assetPath) => {
let columnData = loadData(`${dataPath}columns.json`).then(r => r.json());
let headTemplate = getCompiledTemplate(`${assetPath}templates/head.html`);
let bodyTemplate = getCompiledTemplate(`${assetPath}templates/body.html`);
let itemTemplate = getCompiledTemplate(`${assetPath}templates/item.html`);
let jsonFeedData = fetchCachedFeedData(columnData, itemTemplate);
/*
* Render the head from the cache or network
* Render the body.
* Body has template that brings in config to work out what to render
* If we have data cached let's bring that in.
* Render the footer - contains JS to data bind client request.
*/
const headStream = headTemplate.then(render => render({ columns: columnData }));
const bodyStream = jsonFeedData.then(columns => bodyTemplate.then(render => render({ columns: columns })));
const footStream = loadTemplate(`${assetPath}templates/foot.html`);
let concatStream = new ConcatStream;
headStream.then(stream => stream.pipeTo(concatStream.writable, { preventClose:true }))
.then(() => bodyStream)
.then(stream => stream.pipeTo(concatStream.writable, { preventClose: true }))
.then(() => footStream)
.then(stream => stream.pipeTo(concatStream.writable));
return Promise.resolve(new Response(concatStream.readable, { status: "200" }))
}
Con este modelo en su lugar, en realidad fue relativamente simple hacer que el código y el proceso anteriores funcionen en el servidor * y * en el trabajador del servicio.
Servidor lógico unificado y lógica de trabajador de servicio; mdash; aros y vallas
Ciertamente no fue fácil llegar a una base de código compartido entre el servidor y el cliente, el ecosistema Node + NPM y el ecosistema Web JS son gemelos genéticamente idénticos que han crecido con diferentes familias y cuando finalmente se encuentran hay muchas similitudes y muchas diferencias que deben superarse … Parece una gran idea para una película.
Elegí preferir la web en todo el proyecto. Decidí sobre esto porque no quiero agrupar y cargar código en el navegador del usuario, sino que podría tomar ese golpe en el servidor (puedo escalar esto, el usuario no puede), así que si la API no fue así ‘ soportado en Nodo, entonces tendría que encontrar una cuña compatible.
Estos son algunos de los desafíos que enfrenté.
Un sistema de módulo roto
A medida que tanto el nodo como el ecosistema web crecieron, ambos desarrollaron diferentes formas de componentes, segmentación e importación de código en el momento del diseño. Este fue un problema real cuando estaba tratando de construir este proyecto.
No quería CommonJS en el navegador. Tengo un deseo irracional de alejarme de tantas herramientas de construcción como sea posible y agregar mi desprecio por el funcionamiento de los paquetes, no me dejaron muchas opciones.
Mi solución en el navegador era usar el método plano importScripts, funciona pero depende de un orden de archivos muy específico, como se puede ver en el trabajador del servicio de la siguiente manera:
** sw.js **
importScripts(`/scripts/router.js`);
importScripts(`/scripts/dot.js`);
importScripts(`/scripts/platform/web.js`);
importScripts(`/scripts/platform/common.js`);
importScripts(`/scripts/routes/index.js`);
importScripts(`/scripts/routes/root.js`);
importScripts(`/scripts/routes/proxy.js`);
Y luego, para el nodo, utilicé el mecanismo de carga CommonJS normal en el mismo archivo, pero están bloqueados detrás de una instrucción simple ‘if’ para importar los módulos.
if (typeof module !== 'undefined' && module.exports) {
var doT = require('../dot.js');
...
Mi solución no es una solución escalable, funcionó pero también cubrió mi código con código de pozo que no quería.
Espero con ansias el día en que Node admita ‘módulos’ que los navegadores admitirán … Necesitamos algo simple, sensato, compartido y escalable.
Si revisa el código, verá que este patrón se usa en casi todos los archivos compartidos y en muchos casos fue necesario porque necesitaba importar la implementación de referencia de las transmisiones WHATWG.
Flujos cruzados
Los flujos son probablemente la primitiva más importante que tenemos en la informática (y probablemente la menos entendida) y tanto el Nodo como la Web tienen sus propias soluciones completamente diferentes. Fue una pesadilla para tratar en este proyecto y realmente necesitamos estandarizar una solución unificada (idealmente, DOM Streams).
Afortunadamente hay una implementación completa de Streams API que puede traer a Node, y todo lo que tiene que hacer es escribir un par de utilidades para mapear desde Web Stream -> Node Stream y Node Stream -> Web Corriente.
const nodeReadStreamToWHATWGReadableStream = (stream) => {
return new ReadableStream({
start(controller) {
stream.on('data', data => {
controller.enqueue(data)
});
stream.on('error', (error) => controller.abort(error))
stream.on('end', () => {
controller.close();
})
}
});
};
class FromWHATWGReadableStream extends Readable {
constructor(options, whatwgStream) {
super(options);
const streamReader = whatwgStream.getReader();
pump(this);
function pump(outStream) {
return streamReader.read().then(({ value, done }) => {
if (done) {
outStream.push(null);
return;
}
outStream.push(value.toString());
return pump(outStream);
});
}
}
}
Estas dos funciones auxiliares solo se usaron en el lado Nodo de este proyecto y se usaron para permitirme obtener datos en las API de nodo que no podían aceptar flujos WHATWG y también para pasar datos a las API compatibles con WHATWG Stream que no entendían Node Streams . Necesité específicamente esto para la API fetch en Node.
Una vez que tuve Streams ordenado, el problema final y la incoherencia fue el enrutamiento (casualmente aquí es donde más necesitaba Stream Utils).
Enrutamiento compartido
El ecosistema Node, particularmente Express, es increíblemente conocido y sorprendentemente robusto, pero no tenemos un modelo compartido entre el cliente y el trabajador del servicio.
Hace años escribí LeviRoutes, una sencilla biblioteca del lado del navegador que manejaba ExpressJS como rutas y enganchaba a la API de Historia y también a la API onhashchange. Nadie lo usó, pero yo estaba feliz. Logré quitar el polvo de las telarañas (hacer un tweak o dos) y desplegarlo en esta aplicación. Al mirar el código a continuación puede ver que mi ruta es casi la misma.
** server.js **
app.get('/', (req, res, next) => {
routes['root'](dataPath, assetPath)
.then(response => node.responseToExpressStream(res, response));
});
app.get('/proxy', (req, res, next) => {
routes['proxy'](dataPath, assetPath, req)
.then(response => response.body.pipe(res, {end: true}));
})
** sw.js **
// The proxy server '/proxy'
router.get(`${self.location.origin}/proxy`, (e) => {
e.respondWith(routes['proxy'](dataPath, assetPath, e.request));
}, {urlMatchProperty: 'href'});
// The root '/'
router.get(`${self.location.origin}/$`, (e) => {
e.respondWith(routes['root'](dataPath, assetPath));
}, {urlMatchProperty: 'href'});
Me gustaría ver una solución unificada que traiga la API onfetch del trabajador de servicio al Nodo.
También me gustaría ver un marco tipo “Express” que unifica el enrutamiento de solicitud de código de nodo y navegador. Había diferencias suficientes que significaban que no podía tener la misma fuente en todas partes. Podemos manejar rutas casi exactamente iguales en el cliente y el servidor, por lo que no estamos tan lejos.
No DOM fuera del renderizado
Cuando el usuario no tiene disponible un trabajador de servicios, la lógica para el sitio es bastante tradicional, renderizamos el sitio en el servidor y luego actualizamos incrementalmente el contenido en la página a través de un sondeo AJAX tradicional.
La lógica utiliza la API DOMParser para convertir una fuente RSS en algo que puedo filtrar y consultar en la página.
// Get the RSS feed data.
fetch(`/proxy?url=${feedUrl}`)
.then(feedResponse => feedResponse.text())
// Convert it in to DOM
.then(feedText => {
const parser = new DOMParser();
return parser.parseFromString(feedText,'application/xml');
})
// Find all the news items
.then(doc => doc.querySelectorAll('item'))
// Convert to an array
.then(items => Array.prototype.map.call(items, item => convertRSSItemToJSON(item)))
// Don't add in items that already exist in the page
.then(items => items.filter(item => !!!(document.getElementById(item.guid))))
// DOM Template.
.then(items => items.map(item => applyTemplate(itemTemplate.cloneNode(true), item)))
// Add it into the page
.then(items => items.forEach(item => column.appendChild(item)))
El acceso al DOM de la fuente RSS usando las API estándar en el navegador fue increíblemente útil y me permitió usar mi propio mecanismo de plantillas (del que estoy bastante orgulloso) para actualizar la página dinámicamente.
<template id='itemTemplate'>
<div class="item" data-bind_id='guid'>
<h3><span data-bind_inner-text='title'></span> (<a data-bind_href='link'>#</a>)</h3>
<div data-bind_inner-text='pubDate'></div>
</div>
</template>
<script>
const applyTemplate = (templateElement, data) => {
const element = templateElement.content.cloneNode(true);
const treeWalker = document.createTreeWalker(element, NodeFilter.SHOW_ELEMENT, () => NodeFilter.FILTER_ACCEPT);
while(treeWalker.nextNode()) {
const node = treeWalker.currentNode;
for(let bindAttr in node.dataset) {
let isBindableAttr = (bindAttr.indexOf('bind_') == 0) ? true : false;
if(isBindableAttr) {
let dataKey = node.dataset[bindAttr];
let bindKey = bindAttr.substr(5);
node[bindKey] = data[dataKey];
}
}
}
return element;
};
</script>Estuve muy satisfecho conmigo mismo hasta que me di cuenta de que no podía usar nada de esto en el servidor o en un trabajador de servicio. La única solución que tuve fue traer un analizador XML personalizado y caminar para generar el HTML. Agregó algunas complicaciones y me dejó maldiciendo la web.
A la larga, me encantaría ver un poco más de las DOM API traídas a los trabajadores y también soportadas en Node, pero la solución que tengo funciona incluso si no es óptima.
¿Es posible?
En realidad, hay dos preguntas en esta publicación:
- ¿Es práctico construir sistemas para compartir un servidor y un trabajador de servicios comunes?
- ¿Es posible construir una aplicación web progresiva totalmente progresiva?
¿Es práctico construir sistemas para compartir un servidor y un trabajador de servicios comunes?
Es posible que los sistemas compartan un servidor y un trabajador de servicios comunes, pero ¿es práctico? Me gusta la idea, pero creo que se necesita más investigación, porque si se va JS hasta el final, entonces hay una gran cantidad de problemas entre el nodo y la plataforma web que deben ser resueltos.
Personalmente, me encantaría ver más API “web” en el ecosistema Node.
¿Es posible construir una aplicación web progresiva totalmente progresiva?
Sí.
Estoy muy contento de haber hecho esto. Incluso si no comparte el mismo idioma en el cliente que en el servicio, hay varias cosas críticas que creo que he podido mostrar.
- AppShell no es el único modelo que puede seguir, el punto importante es que el trabajador del servicio _usted obtiene el control sobre la red y usted puede decidir qué es lo mejor para su caso de uso. 2. Es posible construir una experiencia progresivamente representada que utilice el trabajador de servicio para brindar rendimiento y resistencia (así como una sensación de instalación si lo desea). Debe pensar de manera integral, primero debe comenzar a renderizar tanto como pueda en el servidor y luego tomar el control en el cliente. 3. Es posible pensar en experiencias que se construyen “trisomórficamente” (todavía creo que el término es isomorfo es mejor) con una base de código común, una estructura de enrutamiento común y una lógica común compartida entre el cliente, el trabajador del servicio y el servidor.
Lo dejo como una reflexión final: necesitamos investigar más sobre cómo queremos construir aplicaciones web progresivas y debemos seguir presionando sobre los patrones que nos permitan llegar hasta allí. AppShell fue un gran comienzo, no es el final. La representación progresiva y la mejora son la clave del éxito a largo plazo de la web, ningún otro medio puede hacerlo así como tampoco la web.
Si estás interesado en el código, compruébalo en Github pero también puedes jugar con él directamente y volver a mezclarlo en error


Paul Kinlan
Trying to make the web and developers better.




