J’aime les applications Web progressives. J’aime le modèle qu’il propose pour créer des sites Web et des applications de qualité, solides et fiables. J’aime la plate-forme de principe API - service worker - qui permet au modèle PWA de fonctionner.
L’un des pièges dans lesquels nous sommes tombés est “App Shell”. Le modèle App Shell indique que votre site doit présenter un shell complet de votre application (de sorte que l’expérience soit quelque chose même lorsque vous êtes hors ligne) et que vous contrôlez ensuite comment et quand extraire du contenu.
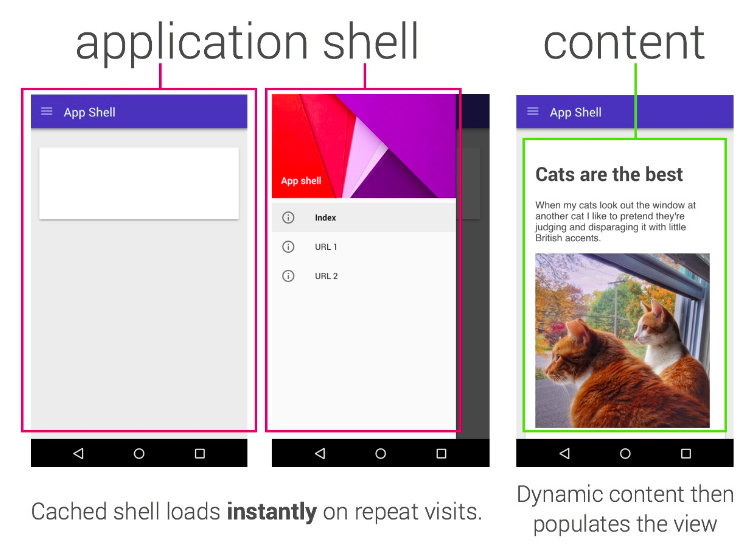
Le modèle App Shell est à peu près analogue à un “SPA” (Single Page App) & mdash; vous chargez le shell, alors chaque navigation ultérieure est gérée directement par JS dans votre page. Cela fonctionne bien dans beaucoup de cas.
Je ne crois pas que App Shell soit le seul * ni le meilleur modèle et, comme toujours, votre choix varie d’une situation à l’autre; Mon propre blog, par exemple, utilise un simple schéma “Stale-Whilst-Revalidate”, chaque page est mise en cache lorsque vous naviguez dans le site et les mises à jour seront affichées dans une actualisation ultérieure. Dans cet article, je voudrais explorer un modèle que j’ai expérimenté récemment.
Vers App Shell ou non App Shell
Dans le modèle classique d’App Shell, il est presque impossible de prendre en charge un rendu progressif et je voulais réaliser un modèle véritablement “progressif” pour la construction d’un site avec un agent de maintenance possédant les propriétés suivantes:
- Cela fonctionne sans JS
- Cela fonctionne quand il n’y a pas de support pour un technicien
- C’est rapide
Je me suis attaché à le démontrer en créant un projet que j’ai toujours voulu construire: A River of News + TweetDeck Hybrid. Pour un ensemble donné de flux RSS, affichez-les en colonnes.
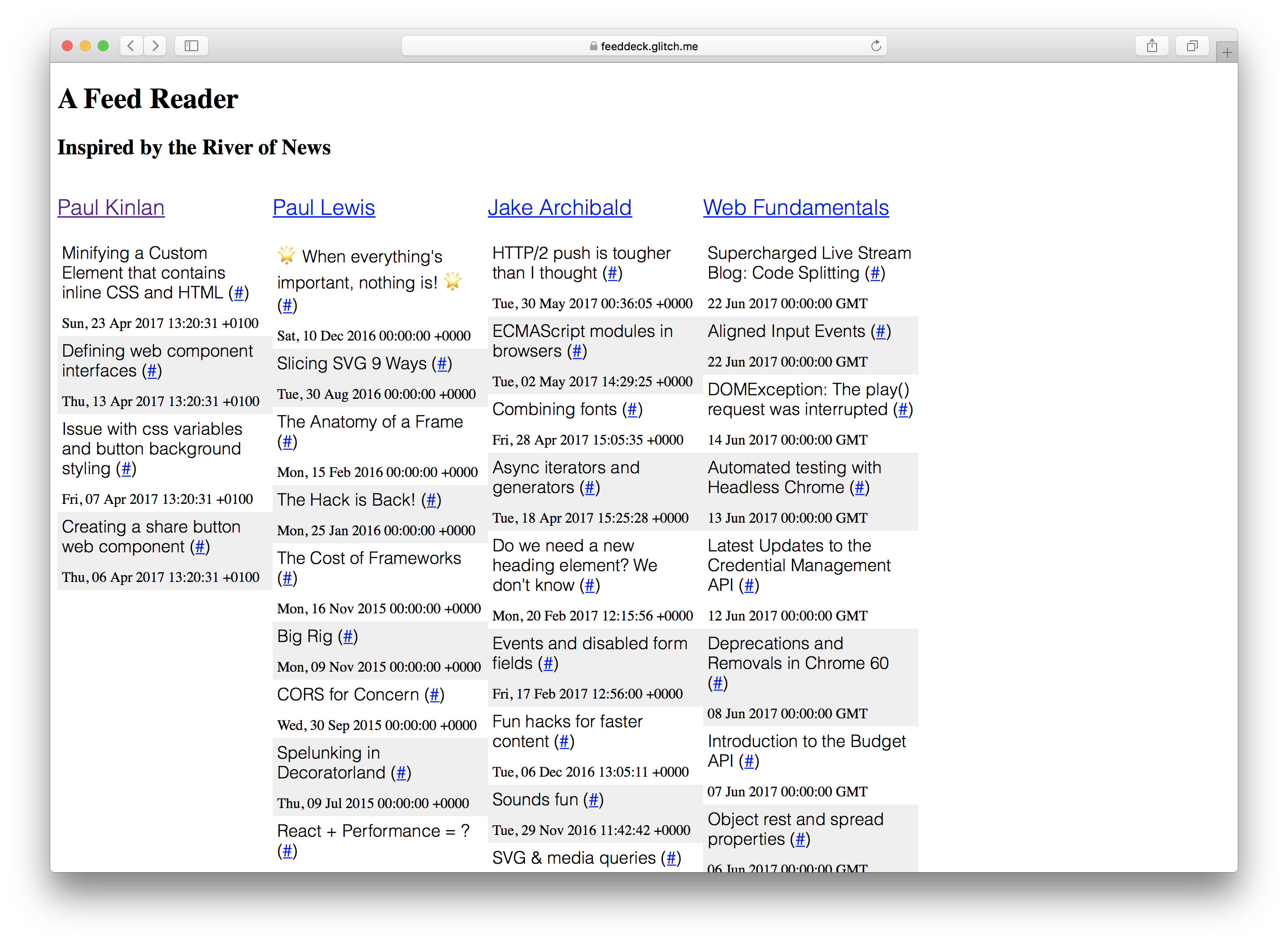
Le “Feed Deck” est une bonne expérience de référence pour l’expérimentation de Service Worker et l’amélioration progressive. Il a un composant rendu par le serveur, il a besoin d’un “shell” pour montrer rapidement quelque chose à l’utilisateur et il a généré dynamiquement du contenu qui doit être mis à jour régulièrement. Enfin, comme il s’agit d’un projet personnel, je n’ai pas besoin d’une infrastructure serveur trop importante pour enregistrer la configuration et l’authentification des utilisateurs.
J’ai réalisé l’essentiel de ce travail et j’ai beaucoup appris au cours du processus. Certaines choses nécessitent encore JS, mais l’application en théorie fonctionne sans JS; Je souhaite que NodeJS ait plus en commun avec les API DOM; Je l’ai construit entièrement sur Chrome OS avec Glitch mais cette dernière pièce est une histoire pour un autre jour.
J’ai défini certaines définitions de ce que “Works” signifie au début du projet.
- “Cela fonctionne sans JS” & mdash; le contenu se charge à l’écran et il y a un chemin clair pour tout ce qui fonctionne sans JS à l’avenir (ou il y a une justification claire de la raison pour laquelle il n’a pas été activé). Je ne peux pas simplement dire “nah”.
- “Cela fonctionne quand il n’y a pas de support pour un Service Worker” & mdash; tout devrait se charger, fonctionner et être extrêmement rapide, mais je suis heureux si cela ne fonctionne pas partout hors ligne.
Mais ce n’était pas la seule histoire, si nous avions JS et le soutien d’un travailleur des services, j’avais le mandat d’assurer:
- Il a chargé instantanément
- Il était fiable et a des caractéristiques de performance prévisibles
- Il a fonctionné entièrement hors ligne
Mea culpa: Si vous regardez le code et que vous l’exécutez dans un ancien navigateur, il y a de fortes chances que cela ne fonctionne pas, j’ai choisi d’utiliser ES6, mais ce n’est pas un obstacle insurmontable.
Si nous devions nous concentrer sur la création d’une expérience qui fonctionnerait sans l’activation de JavaScript, cela signifie que nous devrions rendre le plus possible sur le serveur.
Enfin, mon objectif était secondaire: je voulais explorer la possibilité de partager la logique entre votre prestataire de services et votre serveur… Je dis un mensonge, c’est ce qui m’a le plus excité et beaucoup de l’histoire progressive est tombé du dos de ceci.
Qu’est-ce qui est arrivé en premier? Le serveur ou le technicien?
C’était les deux en même temps. Je dois effectuer un rendu depuis le serveur, mais parce que le technicien de maintenance est assis entre le navigateur et le réseau, j’ai dû réfléchir à la manière dont les deux interagissaient.
J’étais dans une position chanceuse dans le fait que je n’avais pas beaucoup de logique de serveur unique pour pouvoir aborder le problème de manière globale et les deux en même temps. Les principes que je suivais consistaient à réfléchir à ce que je voulais réaliser avec le premier rendu de la page (l’expérience que chaque utilisateur obtiendrait) et les rendus ultérieurs de la page (l’expérience que les utilisateurs engagés obtiendraient) à la fois avec et sans travailleur de service.
** Premier rendu ** & mdash; Il n’y aurait pas de technicien de maintenance disponible. Je devais donc veiller à ce que le premier rendu contienne autant de contenu de la page que possible et à le générer sur le serveur.
Si l’utilisateur a un navigateur qui prend en charge le travailleur du service, je peux faire quelques choses intéressantes. J’ai déjà la logique de modèle créée sur le serveur et il n’y a rien de spécial à leur sujet, alors ils devraient être exactement les mêmes modèles que j’utiliserais directement sur le client. L’agent de service peut récupérer les modèles à l’heure de la mise en service et les stocker pour une utilisation ultérieure.
** Deuxième rendu sans agent de maintenance ** & mdash; Cela devrait agir exactement comme un premier rendu. Nous pourrions tirer parti de la mise en cache HTTP normale, mais la théorie est la même: restituez rapidement votre expérience.
** Deuxième rendu avec service worker ** & mdash; Il devrait agir exactement comme un premier rendu de serveur, mais à l’intérieur du service worker. Je n’ai pas la coquille traditionnelle. Si vous regardez le réseau, vous ne voyez que le code HTML: structure et contenu.

“Le rendu” & mdash; Le streaming est notre ami
J’essayais d’être aussi progressif que possible, ce qui signifie que je dois rendre le plus rapidement possible sur le serveur. J’avais un défi, si je fusionnais toutes les données de tous les flux RSS, le premier rendu serait bloqué par les demandes du réseau aux flux RSS et nous ralentirions donc le premier rendu.
J’ai choisi le chemin suivant:
- Rendre la tête de la page & mdash; c’est relativement statique et cela permet à l’écran d’afficher rapidement les performances.
- Rend la structure de la page en fonction de la configuration (les colonnes) & mdash; pour un utilisateur donné, cela est actuellement statique et il est important de le rendre rapidement visible pour les utilisateurs.
- Rendez les données de la colonne ** si ** nous avons le contenu mis en cache et disponible, nous pouvons le faire à la fois sur le serveur et sur le service worker
- Rendez le pied de page de la page contenant la logique pour mettre à jour périodiquement le contenu de la page.
En tenant compte de ces contraintes, tout doit être asynchrone et je dois tout mettre en œuvre sur le réseau le plus rapidement possible.
Il y a une véritable pénurie de bibliothèques de modèles de diffusion en continu sur le Web. J’ai utilisé streaming-dot par mon bon ami et colleauge Surma qui est un port du framework de templates doT mais avec des générateurs ajoutés pour pouvoir écrire sur un Stream ou Node le contenu entier étant disponible.
Le rendu des données de la colonne (c.-à-d. Ce qui était dans un flux) est l’élément le plus important et nécessite pour l’instant le JavaScript sur le client pour le premier chargement. Le système est configuré pour pouvoir tout afficher sur le serveur pour le premier chargement, mais j’ai choisi de ne pas bloquer sur le réseau.
Si les données ont déjà été récupérées et qu’elles sont disponibles chez le technicien, nous pouvons les communiquer rapidement à l’utilisateur même s’il peut rapidement devenir obsolète.
Le code pour rendre le contenu tout en étant aysnc est relativement procédural et suit le modèle décrit précédemment: nous rendons l’en-tête dans le flux lorsque le modèle est prêt, puis rendons le contenu du corps dans le flux qui attend à son tour le contenu available sera également vidé dans le flux et enfin lorsque tout sera prêt, nous ajouterons dans le pied de page et viderons cela dans le flux de réponses.
Vous trouverez ci-dessous le code que j’utilise sur le serveur et l’agent de maintenance.
const root = (dataPath, assetPath) => {
let columnData = loadData(`${dataPath}columns.json`).then(r => r.json());
let headTemplate = getCompiledTemplate(`${assetPath}templates/head.html`);
let bodyTemplate = getCompiledTemplate(`${assetPath}templates/body.html`);
let itemTemplate = getCompiledTemplate(`${assetPath}templates/item.html`);
let jsonFeedData = fetchCachedFeedData(columnData, itemTemplate);
/*
* Render the head from the cache or network
* Render the body.
* Body has template that brings in config to work out what to render
* If we have data cached let's bring that in.
* Render the footer - contains JS to data bind client request.
*/
const headStream = headTemplate.then(render => render({ columns: columnData }));
const bodyStream = jsonFeedData.then(columns => bodyTemplate.then(render => render({ columns: columns })));
const footStream = loadTemplate(`${assetPath}templates/foot.html`);
let concatStream = new ConcatStream;
headStream.then(stream => stream.pipeTo(concatStream.writable, { preventClose:true }))
.then(() => bodyStream)
.then(stream => stream.pipeTo(concatStream.writable, { preventClose: true }))
.then(() => footStream)
.then(stream => stream.pipeTo(concatStream.writable));
return Promise.resolve(new Response(concatStream.readable, { status: "200" }))
}
Avec ce modèle en place, il était en fait relativement simple d’obtenir le code et le processus ci-dessus fonctionnant sur le serveur * et * dans l’agent de maintenance.
Serveur logique unifié et logique du technicien de maintenance & mdash; cerceaux et obstacles
Il n’est certainement pas facile d’obtenir un code partagé entre le serveur et le client, l’écosystème Node + NPM et l’écosystème Web JS sont comme des jumeaux génétiquement identiques qui ont grandi avec différentes familles et quand ils se rencontrent, les différences doivent être surmontées … Cela semble être une excellente idée pour un film.
J’ai choisi de préférer le Web au projet. Je l’ai décidé parce que je ne veux pas grouper et charger le code dans le navigateur de l’utilisateur, mais je pourrais plutôt prendre ce coup sur le serveur (je peux le faire évoluer, l’utilisateur ne peut pas), donc si l’API n’était pas t pris en charge dans Node, alors je devrais trouver une cale compatible.
Voici quelques défis auxquels j’ai été confronté.
Un système de modules cassé
Au fur et à mesure de la croissance de l’écosystème et de l’écosystème Web, ils ont tous deux développé différents moyens de composants, de segmentation et d’importation de code au moment du design. C’était un vrai problème lorsque j’essayais de construire ce projet.
Je ne voulais pas CommonJS dans le navigateur. J’ai un désir irrationnel de rester aussi loin que possible de l’outillage de construction et d’ajouter mon mépris à la façon dont fonctionne le groupage, cela ne m’a pas laissé beaucoup d’options.
Ma solution dans le navigateur consistait à utiliser la méthode plate importScripts, cela fonctionne, mais cela dépend de l’ordre de fichiers très spécifique, comme on peut le voir dans le cas de l’agent de service comme ceci:
** sw.js **
importScripts(`/scripts/router.js`);
importScripts(`/scripts/dot.js`);
importScripts(`/scripts/platform/web.js`);
importScripts(`/scripts/platform/common.js`);
importScripts(`/scripts/routes/index.js`);
importScripts(`/scripts/routes/root.js`);
importScripts(`/scripts/routes/proxy.js`);
Et puis, pour node, j’ai utilisé le mécanisme de chargement CommonJS normal dans le même fichier, mais ils sont derrière une instruction if simple pour importer les modules.
if (typeof module !== 'undefined' && module.exports) {
var doT = require('../dot.js');
...
Ma solution n’est pas une solution évolutive, elle a fonctionné, mais a également jonché mon code avec du code que je ne voulais pas.
J’attends avec impatience le jour où Node supportera les “modules” supportés par les navigateurs … Nous avons besoin de quelque chose de simple, sain, partagé et évolutif.
Si vous extrayez le code, vous verrez ce modèle utilisé dans presque tous les fichiers partagés et, dans de nombreux cas, il était nécessaire car je devais importer l’implémentation de référence des flux WHATWG (0).
Flux croisés
Les flux sont probablement la primitive la plus importante que nous ayons en informatique (et probablement la moins comprise) et Node et le Web ont leurs propres solutions complètement différentes. C’était un cauchemar à gérer dans ce projet et nous devons vraiment standardiser une solution unifiée (idéalement, les flux DOM).
Heureusement, il existe une implémentation complète de l’API Streams que vous pouvez intégrer à Node, et tout ce que vous avez à faire est d’écrire quelques utilitaires pour les cartographier depuis Web Stream -> Flux de nœuds et flux de nœuds -> Web. Courant.
const nodeReadStreamToWHATWGReadableStream = (stream) => {
return new ReadableStream({
start(controller) {
stream.on('data', data => {
controller.enqueue(data)
});
stream.on('error', (error) => controller.abort(error))
stream.on('end', () => {
controller.close();
})
}
});
};
class FromWHATWGReadableStream extends Readable {
constructor(options, whatwgStream) {
super(options);
const streamReader = whatwgStream.getReader();
pump(this);
function pump(outStream) {
return streamReader.read().then(({ value, done }) => {
if (done) {
outStream.push(null);
return;
}
outStream.push(value.toString());
return pump(outStream);
});
}
}
}
Ces deux fonctions d’assistance n’étaient utilisées que du côté nœud de ce projet et elles me permettaient d’obtenir des données dans les API de nœud qui ne pouvaient pas accepter les flux WHATWG et de transmettre des données aux API compatibles avec WHATWG Stream. . J’avais spécifiquement besoin de ceci pour l’API fetch dans Node.
Une fois les flux triés, le problème final et l’incohérence étaient le routage (ce qui était la coïncidence où j’avais le plus besoin des Stream Utils).
Routage partagé
L’écosystème Node, en particulier Express, est incroyablement bien connu et incroyablement robuste, mais nous n’avons pas de modèle partagé entre le client et le technicien.
Il y a des années, j’ai écrit LeviRoutes, une simple bibliothèque côté navigateur qui traitait des routes comme ExpressJS et qui s’intégraient à l’API History et à l’API onhashchange. Personne ne l’a utilisé mais j’étais heureux. J’ai réussi à dépoussiérer les toiles d’araignée (faire un tweak ou deux) et déployer dans cette application. En regardant le code ci-dessous, vous pouvez voir que mon routage est pratiquement identique.
** server.js **
app.get('/', (req, res, next) => {
routes['root'](dataPath, assetPath)
.then(response => node.responseToExpressStream(res, response));
});
app.get('/proxy', (req, res, next) => {
routes['proxy'](dataPath, assetPath, req)
.then(response => response.body.pipe(res, {end: true}));
})
** sw.js **
// The proxy server '/proxy'
router.get(`${self.location.origin}/proxy`, (e) => {
e.respondWith(routes['proxy'](dataPath, assetPath, e.request));
}, {urlMatchProperty: 'href'});
// The root '/'
router.get(`${self.location.origin}/$`, (e) => {
e.respondWith(routes['root'](dataPath, assetPath));
}, {urlMatchProperty: 'href'});
Je voudrais love pour voir une solution unifiée qui apporte l’API du travailleur du service onfetch dans Node.
Je voudrais aussi aimer voir un framework “Express” qui unifie le routage des requêtes de code Node et Browser. Il y avait juste assez de différences pour que je ne puisse pas avoir la même source partout. Nous pouvons gérer des itinéraires presque identiques sur le client et le serveur, nous ne sommes donc pas loin.
Pas de DOM hors du rendu
Lorsque l’utilisateur n’a pas de technicien de maintenance disponible, la logique du site est assez classique, nous restituons le site sur le serveur, puis nous actualisons le contenu de la page de manière incrémentielle via une interrogation AJAX classique.
La logique utilise l’API DOMParser pour transformer un flux RSS en quelque chose que je peux filtrer et interroger dans la page.
// Get the RSS feed data.
fetch(`/proxy?url=${feedUrl}`)
.then(feedResponse => feedResponse.text())
// Convert it in to DOM
.then(feedText => {
const parser = new DOMParser();
return parser.parseFromString(feedText,'application/xml');
})
// Find all the news items
.then(doc => doc.querySelectorAll('item'))
// Convert to an array
.then(items => Array.prototype.map.call(items, item => convertRSSItemToJSON(item)))
// Don't add in items that already exist in the page
.then(items => items.filter(item => !!!(document.getElementById(item.guid))))
// DOM Template.
.then(items => items.map(item => applyTemplate(itemTemplate.cloneNode(true), item)))
// Add it into the page
.then(items => items.forEach(item => column.appendChild(item)))
Accéder au DOM du flux RSS en utilisant les API standard dans le navigateur était incroyablement utile et cela m’a permis d’utiliser mon propre mécanisme de template (dont je suis assez fier) pour mettre à jour la page dynamiquement.
<template id='itemTemplate'>
<div class="item" data-bind_id='guid'>
<h3><span data-bind_inner-text='title'></span> (<a data-bind_href='link'>#</a>)</h3>
<div data-bind_inner-text='pubDate'></div>
</div>
</template>
<script>
const applyTemplate = (templateElement, data) => {
const element = templateElement.content.cloneNode(true);
const treeWalker = document.createTreeWalker(element, NodeFilter.SHOW_ELEMENT, () => NodeFilter.FILTER_ACCEPT);
while(treeWalker.nextNode()) {
const node = treeWalker.currentNode;
for(let bindAttr in node.dataset) {
let isBindableAttr = (bindAttr.indexOf('bind_') == 0) ? true : false;
if(isBindableAttr) {
let dataKey = node.dataset[bindAttr];
let bindKey = bindAttr.substr(5);
node[bindKey] = data[dataKey];
}
}
}
return element;
};
</script>J’ai été très satisfait de moi jusqu’à ce que je réalise que je ne pouvais pas utiliser cela sur le serveur ou chez un technicien. La seule solution que j’avais était d’apporter un [analyseur XML] personnalisé (0) et de le parcourir pour générer le code HTML. Cela a ajouté une complication et m’a laissé maudire le web.
À long terme, j’aimerais beaucoup que d’autres API DOM soient apportées aux travailleurs et également prises en charge par Node, mais la solution que j’ai fonctionne même si elle n’est pas optimale.
C’est possible?
Il y a vraiment deux questions dans cet article:
- Est-il pratique de construire des systèmes partageant un serveur commun et un agent de service?
- Est-il possible de créer une application Web progressive entièrement progressive?
Est-il pratique de créer des systèmes partageant un serveur et un agent de service communs?
Il est possible de construire des systèmes partageant un serveur commun et un technicien, mais est-ce pratique? J’aime l’idée, mais je pense qu’il faut faire plus de recherches, car si vous passez tout le chemin de JS, il y a beaucoup de problèmes à résoudre entre la plate-forme Node et la plate-forme Web.
Personnellement, j’aimerais voir plus d’API “Web” dans l’écosystème Node.
Est-il possible de construire une application Web progressive entièrement progressive?
Oui.
Je suis très heureux de l’avoir fait. Même si vous ne partagez pas le même langage sur le client que sur le service, il y a un certain nombre de choses critiques que je pense avoir pu montrer.
- AppShell n’est pas le seul modèle que vous puissiez suivre, le point important est que le technicien de maintenance vous contrôle le réseau et que vous pouvez décider de ce qui convient le mieux à votre cas d’utilisation. 2. Il est possible de créer une expérience de rendu progressive qui fait appel à un technicien de maintenance pour apporter des performances et de la résilience (tout comme une sensation installée si vous le souhaitez). Vous devez penser de manière holistique, vous devez d’abord commencer par rendre le plus possible sur le serveur, puis prendre le contrôle du client. 3. Il est possible de réfléchir à des expériences construites de manière “trisomorphique” (je pense toujours que le terme isomorphe est le meilleur) avec une base de code commune, une structure de routage commune et une logique commune partagée par le client, le technicien et le serveur.
Je laisse cela comme une réflexion finale: nous devons étudier plus en détail comment nous voulons construire des applications Web progressives et nous devons continuer à pousser les modèles qui nous permettent d’y arriver. AppShell était un bon début, ce n’est pas la fin. Un rendu et une amélioration progressifs sont la clé du succès à long terme du Web, aucun autre support ne peut le faire aussi bien que le Web.
Si le code vous intéresse, vérifiez-le sur Github mais vous pouvez aussi jouer avec directement et le remixer sur un problème


Paul Kinlan
Trying to make the web and developers better.




