私は[Progressive Web Apps]が好きです(0)。私はそれが良い、しっかりとした、信頼できるウェブサイトとアプリを構築する方法のために提供するモデルが好きです。私は、PWAモデルを動作させるための原則プラットフォームAPI(サービスワーカー)が好きです。
私たちが陥ったトラップの1つは “App Shell“です。 App Shellモデルによれば、サイトはアプリケーションの完全なシェルを提示する必要があるため(オフラインであっても何かを体験できるようにする)、コンテンツをいつどのように取り込むかを制御します。
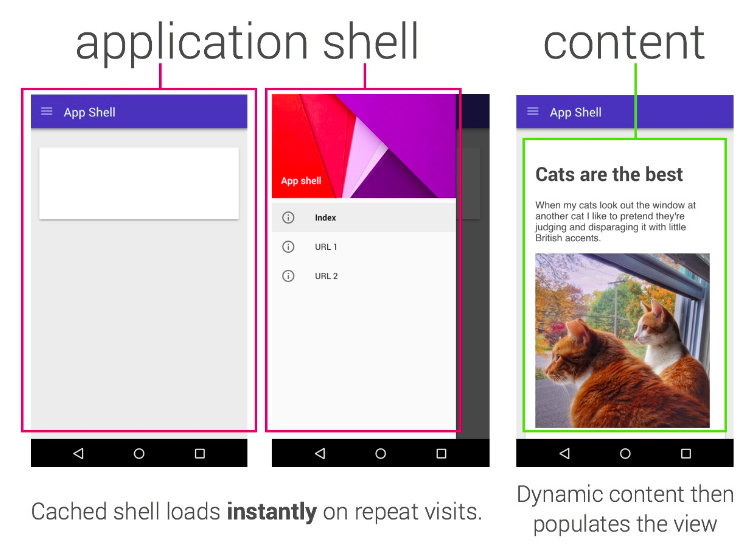
App Shellモデルは、「SPA」(単一ページアプリケーション)とほぼ類似しています。あなたがシェルを読み込んだら、その後のすべてのナビゲーションはあなたのページのJSによって直接処理されます。多くの場合、うまく機能します。
私は、App Shellは*唯一の*最高のモデルではないと信じてはいません。常にあなたの選択は状況によって異なります。私のブログでは、たとえば、サイトを移動するたびにすべてのページがキャッシュされ、後で更新されたときに更新情報が表示される、単純な「失効した状態の再検証」パターンを使用しています。このポストでは、私が最近実験したモデルを探求したいと思います。
#アプリケーションシェルにするかどうか
App Shellの古典的なモデルでは、プログレッシブレンダリングをサポートすることはほとんど不可能で、次のプロパティを持つサービスワーカーを持つサイトを構築するための真の “プログレッシブ”モデルを実現したいと考えていました。
- JSなしで動作します。 *サービスワーカーのサポートがない場合に機能します *速いです
私はこれまで、私が常に作りたかったプロジェクトを作成することでこれを実証することにしました:A River of News + TweetDeck Hybrid与えられたRSSフィードのコレクションが列の形でそれらをレンダリングします。
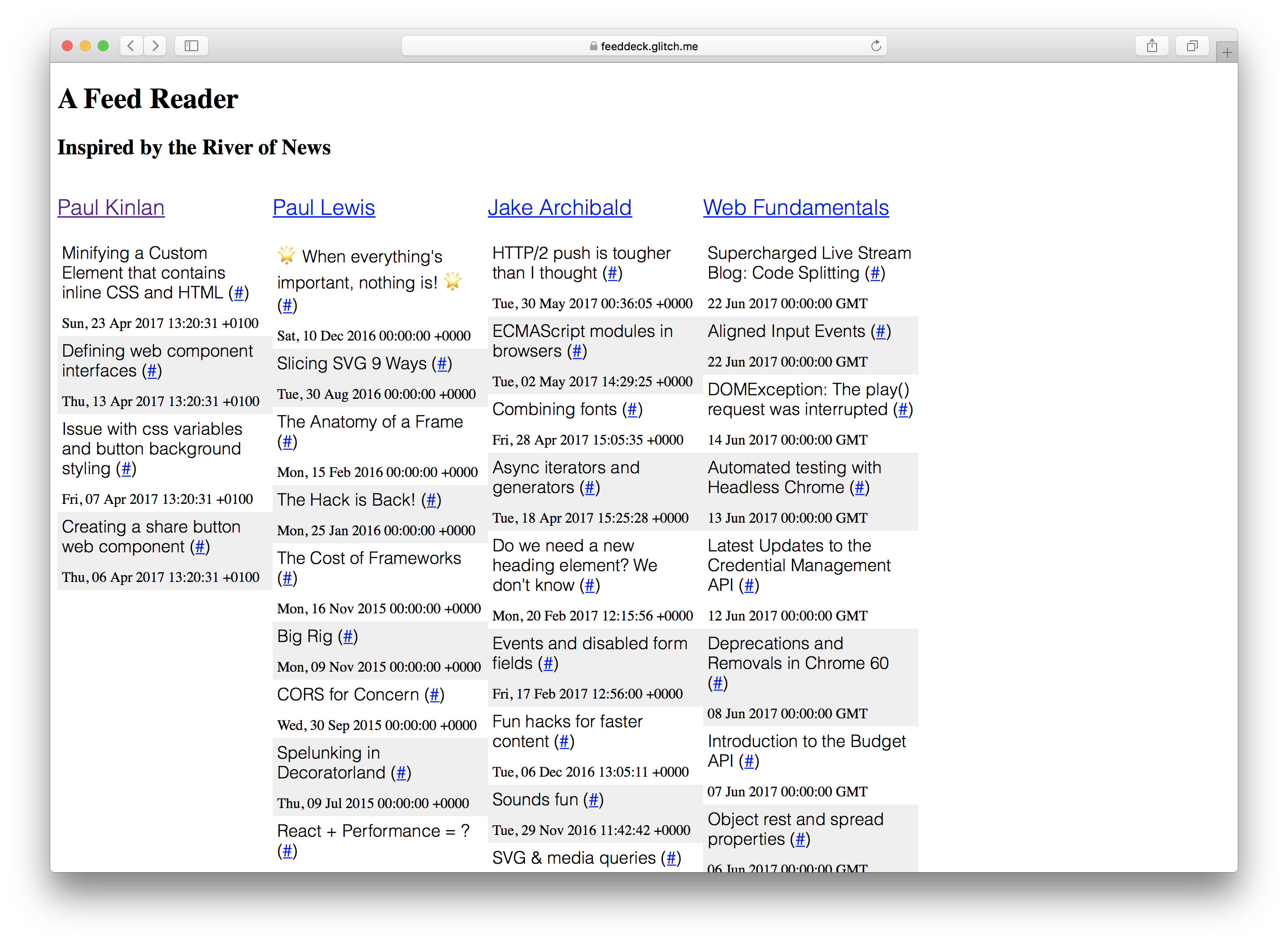
「給餌デッキ」は、サービスワーカーと漸進的な強化を実験する際の参考になる経験です。サーバーにレンダリングされたコンポーネントがあり、ユーザーに何かをすばやく表示するための「シェル」が必要で、定期的に更新する必要があるコンテンツが動的に生成されます。最後に、個人的なプロジェクトであるため、私はユーザーの構成と認証を保存するためにサーバーインフラストラクチャをあまり必要としません。
私はこれのほとんどを達成し、私はその過程で多くのことを学んだ。 JSを必要とするものもありますが、理論上のアプリケーションはJSなしで機能します。私はNodeJSがDOM APIともっと共通していることを望んでいます。私はGlitchを使ってChrome OS上に完全に構築しましたが、この最後の部分は別の日の話です。
私は、プロジェクトの早い段階で「作品」が何を意味するのか、いくつかの定義を設定しました。
*「それはJSなしで動作します」 - コンテンツが画面に表示され、今後JSなしで動作するすべてのコンテンツに対して明確なパスがあります(または、なぜ有効にされなかったのかについての正当な理由があります)。私はちょうど “ナー”と言うことはできません。 * “サービスワーカーのサポートがない場合に機能します” - すべてが読み込まれ、機能し、驚くほど速くなるはずですが、どこでもオフラインで動作しないとうれしいです。
しかしそれが唯一の話ではありませんでした.SSを持ってサービスワーカーをサポートしていれば、私は次のことを保証する義務がありました:
*即座にロード *信頼性が高く予測可能なパフォーマンス特性 *それは完全にオフラインで働いた
Mea culpa:コードを見て、それを古いブラウザで実行すると、うまくいかない可能性が高いので、私はES6を使用することにしましたが、これは決して許されないハードルではありません。
JavaScriptを有効にしないで機能した経験を積み重ねることに焦点を当てるならば、できるだけサーバー上でレンダリングする必要があると考えています。
最後に、私は第二の目標を持っていました:サービスワーカーとサーバーの間でロジックを共有することがどれほど実現可能であるかを探求したいと思っていました….私は嘘をついています。これは私に最も多くの利益漸進的な物語の後ろからこれは落ちた。
#何が最初に来たのか。サーバーまたはサービスワーカー?
それは同時に両方でした。サーバーからレンダリングする必要がありますが、サービスワーカーがブラウザとネットワークの間に位置するため、2人がどのように相互作用したかについて考える必要がありました。
私は幸運な立場にいました。私は多くのユニークなサーバーロジックを持っていなかったので、問題を全体的にかつ同時に解決することができました。私が従った原則は、ページの最初のレンダリング(すべてのユーザーが得られるエクスペリエンス)とその後のページのレンダリング(ユーザーの関心を引くエクスペリエンス)で、サービスワーカー。
最初のレンダリング - 利用可能なサービスワーカーは存在しないので、最初のレンダリングができるだけ多くのページコンテンツを含み、それがサーバー上で生成されるようにする必要がありました。
ユーザーがサービスワーカーをサポートするブラウザを持っている場合、私は興味深いことをいくつか実行できます。私はすでにテンプレートロジックをサーバー上に作成してあり、特別なことは何もないので、クライアントで直接使用するテンプレートと同じテンプレートにする必要があります。サービスワーカーは oninstall時にテンプレートを取得し、後で使用できるように保存することができます。
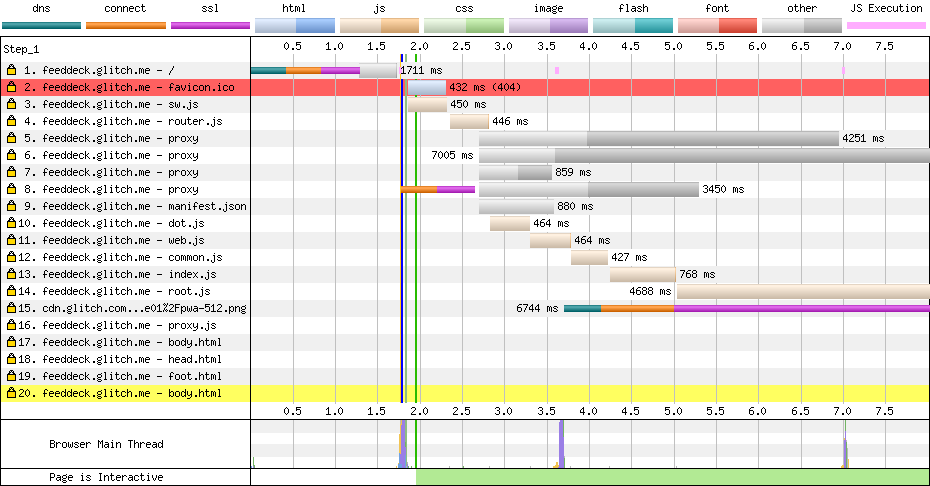
サービスワーカーなしの2番目のレンダリング—最初のレンダリングとまったく同じように動作するはずです。通常のHTTPキャッシュの恩恵を受けるかもしれませんが、理論は同じです。経験を素早くレンダリングしてください。
** 2番目のレンダリングは_with_サービスワーカー**—最初のサーバレンダリングのように*正確に*動作するはずですが、すべてサービスワーカーの内部にあります。私は伝統的なシェルを持っていません。ネットワークを見ると、HTML:structure and contentが完全に縫い合わされています。
title = “フィードデッキ&2番目の負荷(サービスワーカー制御)”>}} 
“レンダリング”—ストリーミングは私たちの友人です
私はできるだけプログレッシブにしようとしていました。つまり、サーバー上でできるだけ迅速にレンダリングする必要があります。私はすべてのRSSフィードからすべてのデータをマージした場合、最初のレンダリングがRSSフィードへのネットワーク要求によってブロックされるため、最初のレンダリングを遅くします。
私は以下の道を選んだ:
*ページの頭をレンダリングしてください。それは比較的静的であり、スクリーンにこれを得ることは、速やかに性能を助けます。 *設定(列)に基づいてページの構造をレンダリングします。特定のユーザーの場合、これは現在静的であり、すばやく表示することはユーザーにとって重要です。 *列データをレンダリングする** **コンテンツがキャッシュされて利用可能である場合、サーバーとサービスワーカーの両方でこれを行うことができます *ロジックを含むページのフッターをレンダリングして、ページの内容を動的に更新します。
これらの制約を念頭に置いて、すべてが非同期である必要があり、できるだけ早くネットワーク上のすべてを取得する必要があります。
Web上にテンプレートライブラリをストリーミングするのは本当に不足しています。私はテンプレートフレームワークdoTのポートであるが、ノードやDOMストリームに書き込むことができ、ブロックしないようにジェネレータを追加した良い友達であるSurmaによってstreaming-dotを使用しましたコンテンツ全体が利用可能です。
列データのレンダリング(すなわち、フィード内にあったもの)が最も重要な部分であり、これは最初のロードのためにクライアント上でJavaScriptを必要とします。システムは最初の負荷のためにサーバ上のすべてをレンダリングできるように設定されていますが、私はネットワーク上でブロックしないことを選択しました。
データがすでに取得され、サービスワーカーで利用可能な場合、迅速に失効する可能性がある場合でも、迅速にデータを取得することができます。
コンテンツをレンダリングするコードは、比較的手続き的で、先に説明したモデルに従います。テンプレートの準備ができたらストリームにヘッダーをレンダリングし、コンテンツをストリームにレンダリングします。利用可能なストリームもストリームにフラッシュされ、最後にすべてが準備ができたらフッターに追加して応答ストリームにフラッシュします。
以下は、サーバーとサービスワーカーで使用するコードです。
const root = (dataPath, assetPath) => {
let columnData = loadData(`${dataPath}columns.json`).then(r => r.json());
let headTemplate = getCompiledTemplate(`${assetPath}templates/head.html`);
let bodyTemplate = getCompiledTemplate(`${assetPath}templates/body.html`);
let itemTemplate = getCompiledTemplate(`${assetPath}templates/item.html`);
let jsonFeedData = fetchCachedFeedData(columnData, itemTemplate);
/*
* Render the head from the cache or network
* Render the body.
* Body has template that brings in config to work out what to render
* If we have data cached let's bring that in.
* Render the footer - contains JS to data bind client request.
*/
const headStream = headTemplate.then(render => render({ columns: columnData }));
const bodyStream = jsonFeedData.then(columns => bodyTemplate.then(render => render({ columns: columns })));
const footStream = loadTemplate(`${assetPath}templates/foot.html`);
let concatStream = new ConcatStream;
headStream.then(stream => stream.pipeTo(concatStream.writable, { preventClose:true }))
.then(() => bodyStream)
.then(stream => stream.pipeTo(concatStream.writable, { preventClose: true }))
.then(() => footStream)
.then(stream => stream.pipeTo(concatStream.writable));
return Promise.resolve(new Response(concatStream.readable, { status: "200" }))
}
このモデルを使用すると、上記のコードを取得してサービスワーカーのサーバー*と*で作業するのは、実際には比較的簡単でした。
##統一されたロジックサーバーとサービスワーカーロジック。フープとハードル
サーバとクライアントの間の共有コードベースに到達することは確かに容易ではなかったが、Node + NPMエコシステムとWeb JSエコシステムは遺伝的に同一の双子のようなもので、異なる家族で成長した。克服する必要がある違い…映画のための素晴らしい考えのように聞こえる。
私はプロジェクト全体でWebを好むことにしました。私はバンドルしてコードをユーザーのブラウザにロードするのではなく、むしろサーバー上でそのヒットを取ることができます(私はこれをスケールすることができます、ユーザーはできません)ので、ノードでサポートされていれば、互換シムを見つけなければなりません。
ここで私が直面したいくつかの課題があります。
###壊れたモジュールシステム
ノードとWebエコシステムの両方が成長したので、設計時にコードをコンポーネント化、セグメント化、およびインポートするさまざまな方法を開発しました。私がこのプロジェクトを構築しようとしたとき、これは本当の問題でした。
私はブラウザでCommonJSに行きたくなかった。私はできるだけ多くのツールを作ることから離れ、バンドルのしくみを軽視したいという不合理な欲求を持っています。
ブラウザの私の解決策はフラットな importScriptsメソッドを使用することでしたが、それは動作しますが、非常に特定のファイルの順序に依存しています。
** sw.js **
importScripts(`/scripts/router.js`);
importScripts(`/scripts/dot.js`);
importScripts(`/scripts/platform/web.js`);
importScripts(`/scripts/platform/common.js`);
importScripts(`/scripts/routes/index.js`);
importScripts(`/scripts/routes/root.js`);
importScripts(`/scripts/routes/proxy.js`);
そして、ノードでは、同じファイルで普通のCommonJSの読み込み機構を使いましたが、モジュールをインポートするために単純な ifステートメントの後ろにゲートされています。
if (typeof module !== 'undefined' && module.exports) {
var doT = require('../dot.js');
...
私の解決策はスケーラブルな解決策ではなく、うまく機能していました。
私は、Nodeがブラウザがサポートする modulesをサポートする日を楽しみにしています…シンプルで、シンプルで、共有され、スケーラブルなものが必要です。
コードをチェックアウトすると、ほぼすべての共有ファイルでこのパターンが使用されていることがわかります。なぜなら、WHATWGストリーム参照実装をインポートする必要があったためです。
###クロスストリーム
ストリームはおそらくコンピューティングで最も重要なプリミティブであり(おそらく最も理解されていない)、ノードとWebの両方がそれぞれ異なるソリューションを持っています。このプロジェクトでは対処するのが夢中であり、統一されたソリューション(理想的にはDOM Streams)を標準化する必要があります。
幸いなことに、Nodeに取り込むことができるStreams APIの完全な実装があります。あなたがしなければならないことは、Web Stream - > Node StreamとNode Stream - > Webストリーム。
const nodeReadStreamToWHATWGReadableStream = (stream) => {
return new ReadableStream({
start(controller) {
stream.on('data', data => {
controller.enqueue(data)
});
stream.on('error', (error) => controller.abort(error))
stream.on('end', () => {
controller.close();
})
}
});
};
class FromWHATWGReadableStream extends Readable {
constructor(options, whatwgStream) {
super(options);
const streamReader = whatwgStream.getReader();
pump(this);
function pump(outStream) {
return streamReader.read().then(({ value, done }) => {
if (done) {
outStream.push(null);
return;
}
outStream.push(value.toString());
return pump(outStream);
});
}
}
}
これらの2つのヘルパー関数は、このプロジェクトのNode側でのみ使用され、WHATWGストリームを受け入れることができなかったノードAPIにデータを取得させ、同様にノードストリームを理解できなかったWHATWG Stream互換APIにデータを渡すために使用されました。私は特にNodeの fetch APIのためにこれを必要としました。
ストリームをソートした後、最終的な問題と不一致はルーティングです(同時に、これはストリーム・ユーティリティを最も必要とした場所です)。
###共有ルーティング
Node ecosystem、特にExpressは非常によく知られており、驚くほど堅牢ですが、クライアントとサービスワーカーの間に共有モデルはありません。
数年前、私は、ExpressJSをルートのように扱い、History APIと onhashchange APIにフックした単純なブラウザサイドライブラリLeviRoutesを書きました。誰もそれを使用していないが、私は幸せだった。私は、cobwebsのほこり(2つの調整か2つを作る)を管理し、このアプリケーションに展開しました。下のコードを見ると、私のルーティングはまったく同じです。
** server.js **
app.get('/', (req, res, next) => {
routes['root'](dataPath, assetPath)
.then(response => node.responseToExpressStream(res, response));
});
app.get('/proxy', (req, res, next) => {
routes['proxy'](dataPath, assetPath, req)
.then(response => response.body.pipe(res, {end: true}));
})
** sw.js **
// The proxy server '/proxy'
router.get(`${self.location.origin}/proxy`, (e) => {
e.respondWith(routes['proxy'](dataPath, assetPath, e.request));
}, {urlMatchProperty: 'href'});
// The root '/'
router.get(`${self.location.origin}/$`, (e) => {
e.respondWith(routes['root'](dataPath, assetPath));
}, {urlMatchProperty: 'href'});
私は、サービスワーカーのonfetch APIをノードに持ち込む統一されたソリューションを見ていきたいと思っています。
また、ノードとブラウザのコードリクエストルーティングを統一した「Express」フレームワークを見るのにも夢中になります。私はどこでも同じ出所を持つことができなかっただけの十分な違いがありました。私たちは、クライアントとサーバー上でほぼ同じルートを扱うことができるので、遠く離れているわけではありません。
###レンダリングの外側にDOMはありません
ユーザーに利用可能なサービスワーカーがない場合、サイトのロジックはかなり伝統的です。サーバー上のサイトをレンダリングし、従来のAJAXポーリングを使用してページ内のコンテンツを段階的に更新します。
ロジックは DOMParser APIを使ってRSSフィードをページ内でフィルタリングしてクエリできるようにします。
// Get the RSS feed data.
fetch(`/proxy?url=${feedUrl}`)
.then(feedResponse => feedResponse.text())
// Convert it in to DOM
.then(feedText => {
const parser = new DOMParser();
return parser.parseFromString(feedText,'application/xml');
})
// Find all the news items
.then(doc => doc.querySelectorAll('item'))
// Convert to an array
.then(items => Array.prototype.map.call(items, item => convertRSSItemToJSON(item)))
// Don't add in items that already exist in the page
.then(items => items.filter(item => !!!(document.getElementById(item.guid))))
// DOM Template.
.then(items => items.map(item => applyTemplate(itemTemplate.cloneNode(true), item)))
// Add it into the page
.then(items => items.forEach(item => column.appendChild(item)))
ブラウザの標準APIを使用してRSSフィードのDOMにアクセスすることは非常に便利で、ページを動的に更新する独自のテンプレートメカニズム(私はむしろ誇りに思っています)を使用することができました。
<template id='itemTemplate'>
<div class="item" data-bind_id='guid'>
<h3><span data-bind_inner-text='title'></span> (<a data-bind_href='link'>#</a>)</h3>
<div data-bind_inner-text='pubDate'></div>
</div>
</template>
<script>
const applyTemplate = (templateElement, data) => {
const element = templateElement.content.cloneNode(true);
const treeWalker = document.createTreeWalker(element, NodeFilter.SHOW_ELEMENT, () => NodeFilter.FILTER_ACCEPT);
while(treeWalker.nextNode()) {
const node = treeWalker.currentNode;
for(let bindAttr in node.dataset) {
let isBindableAttr = (bindAttr.indexOf('bind_') == 0) ? true : false;
if(isBindableAttr) {
let dataKey = node.dataset[bindAttr];
let bindKey = bindAttr.substr(5);
node[bindKey] = data[dataKey];
}
}
}
return element;
};
</script>私は自分がサーバやサービスワーカーでこれを使うことができないことに気づくまで、私はとても満足していました。私が持っていた唯一の解決策は、カスタムXMLパーサーを組み込んでHTMLを生成することでした。それはいくつかの合併症を追加し、私にウェブを呪われたままにしました。
長期的には、DOM APIのいくつかが労働者にもたらされ、Nodeでもサポートされているのを見たいと思っていますが、最適ではない場合でも私の解決策はあります。
# 出来ますか?
この投稿には本当に2つの質問があります:
*共通のサーバーとサービスワーカーを共有するシステムを構築することは現実的ですか? *完全プログレッシブプログレッシブWebアプリケーションを構築することは可能ですか?
##共通のサーバーとサービスワーカーを共有するシステムを構築することは現実的ですか?
システムを構築して共通のサーバーとサービスワーカーを共有することは可能ですが、実用的ですか?アイデアは気に入っていますが、JSを進めていけば、ノードとWebプラットフォームの間には多大な問題があります。
個人的には、ノードエコシステムでより多くの「Web」APIを見たいと思っています。
##完全プログレッシブプログレッシブウェブアプリケーションを構築することは可能ですか?
はい。
私はこれをしたことを非常に嬉しく思います。あなたが同じ言語を奉仕の時と同じように共有していないとしても、私が見せてくれたと思う多くの重要なことがあります。
- AppShellは、あなたが従うことができる唯一のモデルではありません。重要なポイントは、サービスワーカーがネットワークを制御し、ユースケースに最適なものを決定できることです。 2.サービスワーカーを使用してパフォーマンスと復元力を提供する、徐々にレンダリングされたエクスペリエンスを構築することができます(また、必要に応じてインストールされた感覚)。ホリスティックに考える必要があります。サーバーでレンダリングを始めてから、クライアントで制御を開始する必要があります。 3.共通のコードベース、共通のルーティング構造、共通ロジックをクライアント、サービスワーカー、サーバー間で共有することで、 “同形的に”構築された経験について考えることができます(私はまだ同形という言葉が一番良いと思います)。
私は最終的な考えとしてこれを残しています:進歩的なWebアプリケーションを構築する方法についてもっと調べる必要があります。私たちはそこに到達できるようなパターンを続けていく必要があります。 AppShellは素晴らしいスタートでしたが、それは終わりではありません。プログレッシブレンダリングとエンハンスメントは、ウェブの長期的な成功の鍵であり、ウェブだけでなく他の媒体もこれを行うことはできません。
あなたがコードに興味があるなら、Githubでチェックアウトする、それと一緒に遊んでも構いません。


Paul Kinlan
Trying to make the web and developers better.




