У меня было немного простоя после Google IO, и я хотел покончить с долговременным зудом, который у меня был. Я просто хочу иметь возможность копировать текст, который хранится внутри изображений в браузере. Это все. Я думаю, что это будет отличная особенность для всех.
Нелегко добавить функциональность непосредственно в Chrome, но я знаю, что могу использовать систему намерений на Android, и теперь я могу сделать это с помощью Интернета (или, по крайней мере, Chrome на Android).
Два новых дополнения к веб-платформе - Share Target Level 2 (или, как мне нравится называть это File Share) и TextDetector в API обнаружения формы - have allowed me to build a utility that I can Share images to and get the text held inside them .
Базовая реализация относительно проста: вы создаете Share Share Target и обработчик в Service Worker, а затем, когда у вас есть образ, которым поделился пользователь, вы запускаете TextDetector на нем.
Share Target API позволяет вашему веб-приложению быть частью собственной подсистемы совместного использования, и в этом случае вы теперь можете зарегистрироваться для обработки всех типов image/* , объявив его внутри Web App Manifest следующим образом.
"share_target": {
"action": "/index.html",
"method": "POST",
"enctype": "multipart/form-data",
"params": {
"files": [
{
"name": "file",
"accept": ["image/*"]
}
]
}
}
Когда ваш PWA установлен, вы увидите его во всех местах, где вы обмениваетесь изображениями следующим образом:
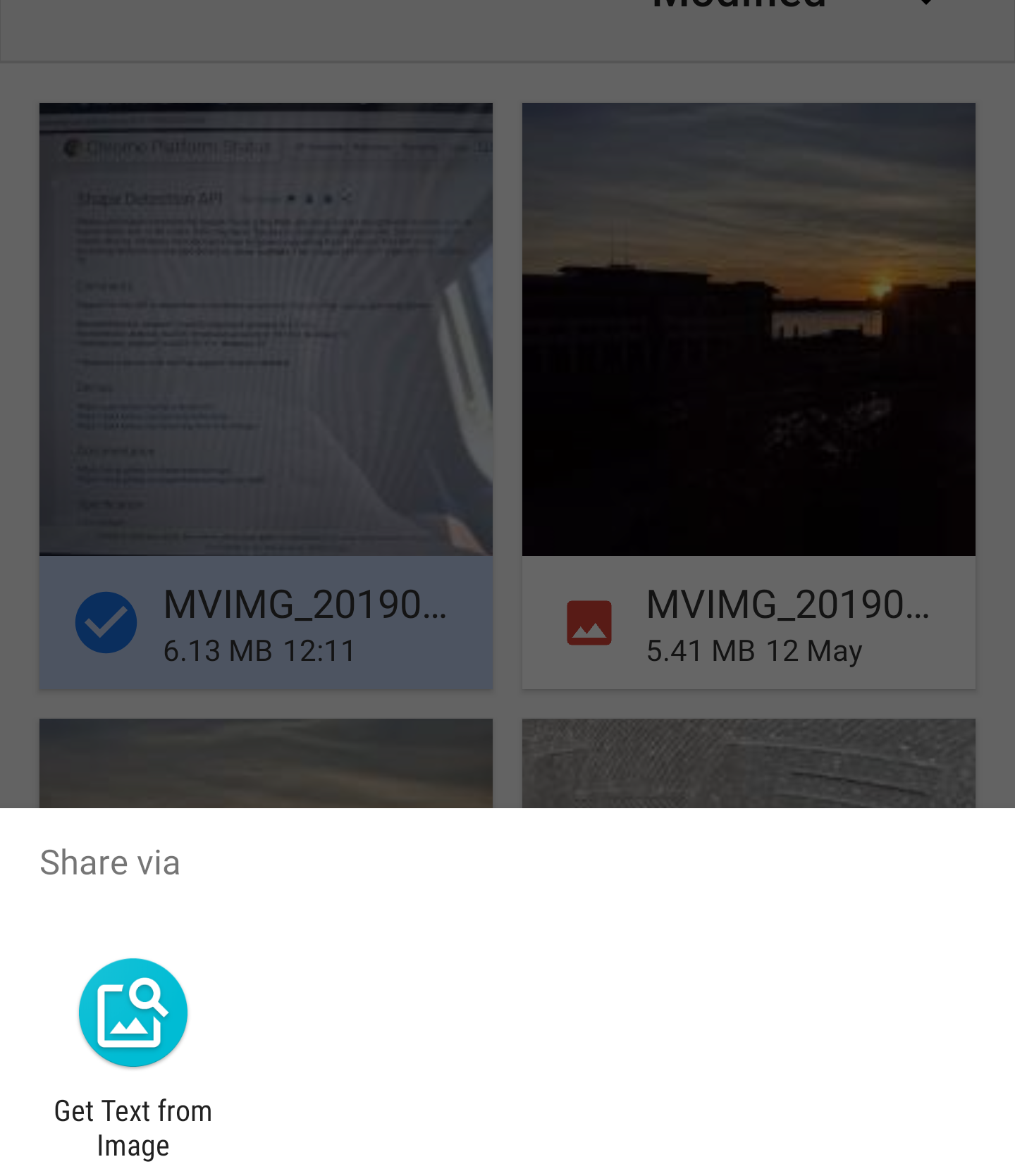
API Share Target рассматривает совместное использование файлов как форму сообщения. Когда файл fetch в веб-приложение, сервисный работник активируется, обработчик fetch вызывается с данными файла. Данные теперь находятся внутри Service Worker, но они мне нужны в текущем окне, чтобы я мог их обработать, служба знает, какое окно вызвало запрос, чтобы вы могли легко ориентироваться на клиента и отправлять ему данные.
self.addEventListener('fetch', event => {
if (event.request.method === 'POST') {
event.respondWith(Response.redirect('/index.html'));
event.waitUntil(async function () {
const data = await event.request.formData();
const client = await self.clients.get(event.resultingClientId || event.clientId);
const file = data.get('file');
client.postMessage({ file, action: 'load-image' });
}());
return;
}
...
...
}
Когда изображение находится в пользовательском интерфейсе, я обрабатываю его с помощью API обнаружения текста.
navigator.serviceWorker.onmessage = (event) => {
const file = event.data.file;
const imgEl = document.getElementById('img');
const outputEl = document.getElementById('output');
const objUrl = URL.createObjectURL(file);
imgEl.src = objUrl;
imgEl.onload = () => {
const texts = await textDetector.detect(imgEl);
texts.forEach(text => {
const textEl = document.createElement('p');
textEl.textContent = text.rawValue;
outputEl.appendChild(textEl);
});
};
...
};
Самая большая проблема заключается в том, что браузер не поворачивает изображение естественным образом (как вы можете видеть ниже), а API обнаружения формы необходимо, чтобы текст был в правильной ориентации чтения.
Я использовал довольно простой в использовании EXIF-Js library чтобы обнаружить вращение, а затем выполнить некоторые базовые манипуляции с холстом, чтобы переориентировать изображение.
EXIF.getData(imgEl, async function() {
// http://sylvana.net/jpegcrop/exif_orientation.html
const orientation = EXIF.getTag(this, 'Orientation');
const [width, height] = (orientation > 4)
? [ imgEl.naturalWidth, imgEl.naturalHeight ]
: [ imgEl.naturalHeight, imgEl.naturalWidth ];
canvas.width = width;
canvas.height = height;
const context = canvas.getContext('2d');
// We have to get the correct orientation for the image
// See also https://stackoverflow.com/questions/20600800/js-client-side-exif-orientation-rotate-and-mirror-jpeg-images
switch(orientation) {
case 2: context.transform(-1, 0, 0, 1, width, 0); break;
case 3: context.transform(-1, 0, 0, -1, width, height); break;
case 4: context.transform(1, 0, 0, -1, 0, height); break;
case 5: context.transform(0, 1, 1, 0, 0, 0); break;
case 6: context.transform(0, 1, -1, 0, height, 0); break;
case 7: context.transform(0, -1, -1, 0, height, width); break;
case 8: context.transform(0, -1, 1, 0, 0, width); break;
}
context.drawImage(imgEl, 0, 0);
}
И вуаля, если вы поделитесь изображением с приложением, оно будет вращать изображение, а затем анализировать его, возвращая вывод найденного текста.
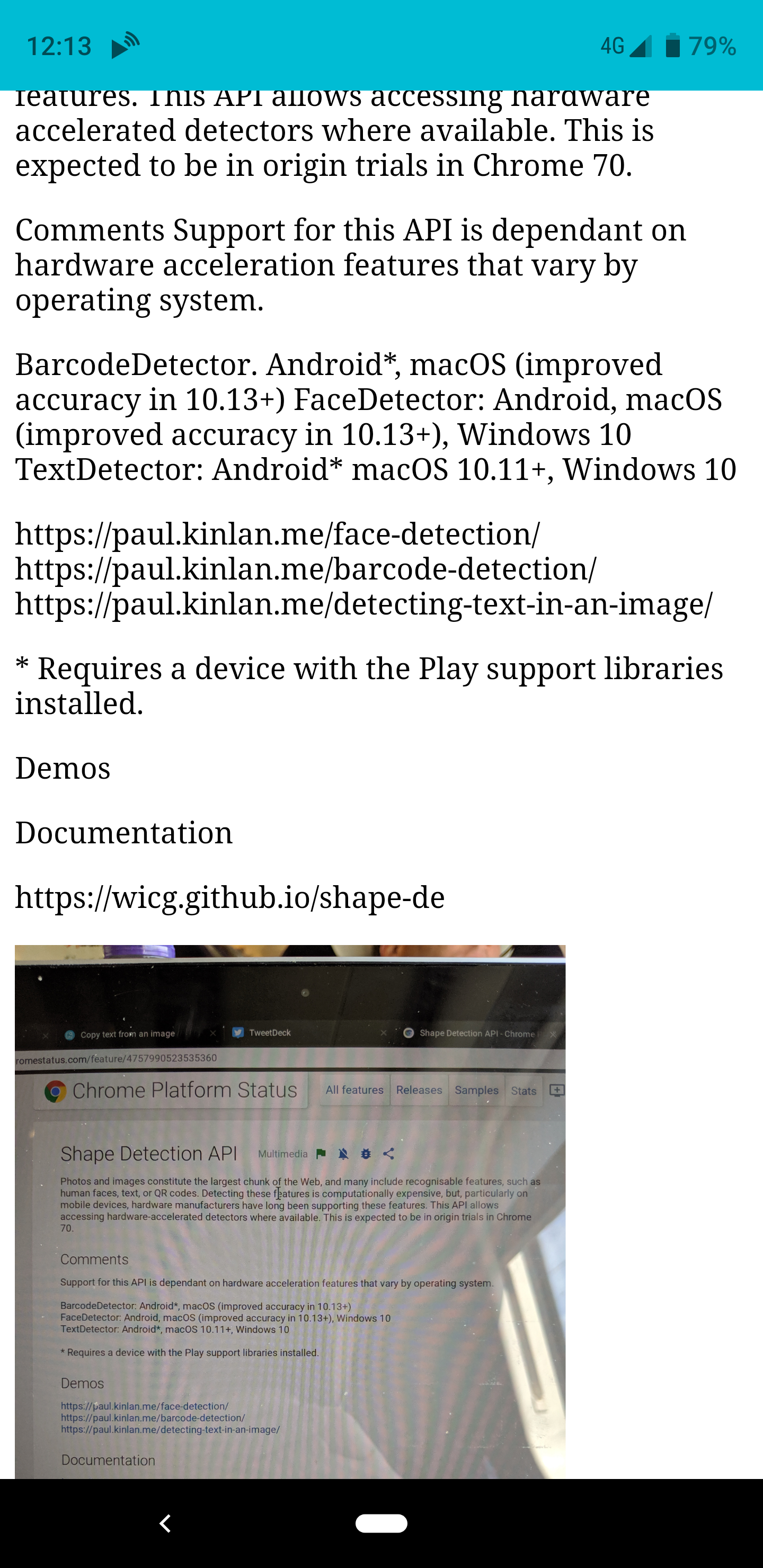
Создать этот маленький эксперимент было невероятно весело, и он сразу пригодился мне. Это, однако, выделить inconsistency of the web platform . Эти API доступны не во всех браузерах, они недоступны даже во всех версиях Chrome - это означает, что, когда я пишу эту статью для Chrome OS, я не могу использовать приложение, но в то же время могу использовать его … О боже, так круто.


Paul Kinlan
Trying to make the web and developers better.




