Мне нравится Progressive Web Apps. Мне нравится модель, которую она предлагает для создания хороших, надежных веб-сайтов и приложений. Мне нравится API-интерфейс основной платформы - рабочий сервис, который позволяет модели PWA работать.
Одна из ловушек, в которую мы попали, - «Shell приложения». Модель App Shell говорит, что ваш сайт должен представить полную оболочку вашего приложения (чтобы опыт был чем-то даже в автономном режиме), а затем вы определяете, как и когда нужно потянуть контент.
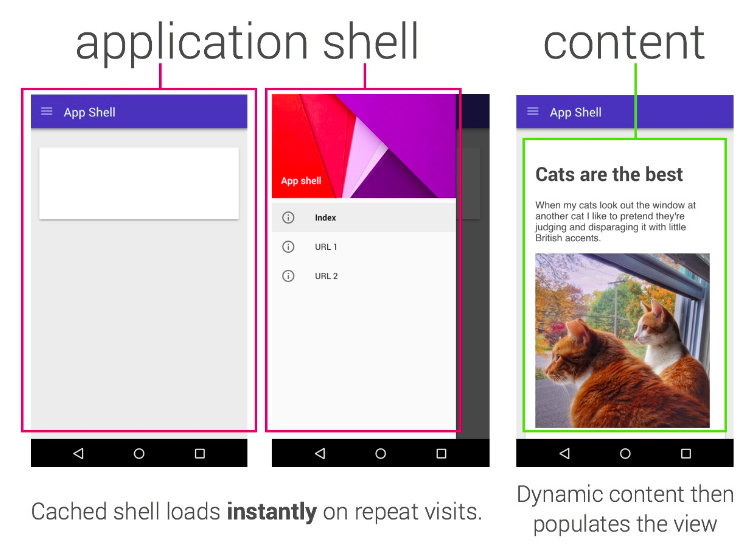
Модель приложения Shell примерно аналогична модели «SPA» (одностраничное приложение); вы загружаете оболочку, затем каждая последующая навигация обрабатывается JS непосредственно на вашей странице. Он работает хорошо во многих случаях.
Я не считаю, что App Shell - это только * или лучшая модель, и, как всегда, ваш выбор варьируется от ситуации к ситуации; например, в моем собственном блоге используется простой шаблон «Stale-Whil-Revalidate», каждая страница кэшируется, когда вы перемещаетесь по сайту, и обновления будут отображаться при последующем обновлении; в этом посте я хотел бы изучить модель, с которой я недавно экспериментировал.
В оболочку приложения или оболочку приложения
В классической модели App Shell почти невозможно поддерживать прогрессивный рендеринг, и я хотел достичь по-настоящему «прогрессивной» модели для создания сайта с сервисным работником, который обладал следующими свойствами:
- Он работает без JS
- Он работает, когда нет поддержки для Рабочего Рабочего
- Это быстро
Я решил продемонстрировать это, создав проект, который я всегда хотел построить: Река Новости + TweetDeck Hybrid. Для данного сборника RSS-каналов они отображаются в колонке.
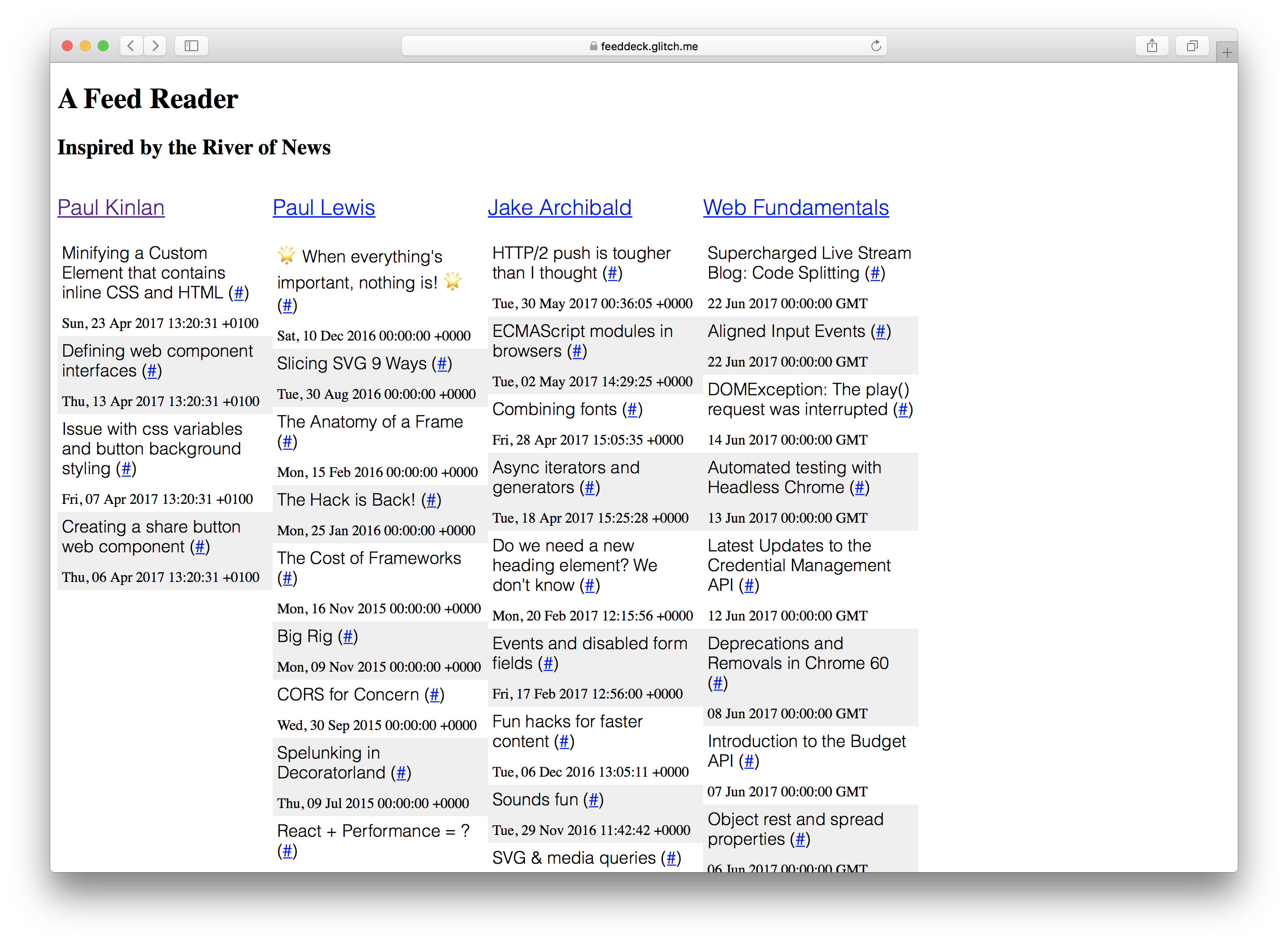
«Feed Deck» - хороший справочный опыт для экспериментов с Service Worker и прогрессивным улучшением. Он имеет компонент, обработанный сервером, он требует, чтобы «оболочка» быстро показывала что-то пользователю, и у него есть динамически созданный контент, который необходимо регулярно обновлять. Наконец, поскольку это персональный проект, мне не нужно слишком много серверной инфраструктуры для сохранения конфигурации пользователя и аутентификации.
Я добился большей части этого, и я многому научился во время этого процесса. Некоторые вещи по-прежнему требуют JS, но приложение в теории функционирует без JS; Я хочу, чтобы NodeJS имел больше общего с DOM API; Я построил его полностью на Chrome OS с помощью Glitch, но этот последний фрагмент - это история на другой день.
Я установил некоторые определения того, что означает «Работы» на раннем этапе проекта.
- «Это работает без JS» & mdash; содержимое загружается на экран, и есть четкий путь для него для всего, что работает без JS в будущем (или есть явное обоснование того, почему он не был включен). Я не могу просто сказать «нет».
- «Это работает, когда нет поддержки для Рабочего Рабочего» & mdash; все должно загружаться, функционировать и быть невероятно быстрым, но я счастлив, если он не работает в автономном режиме везде.
Но это была не единственная история, если бы мы имели JS и поддерживали сервисного работника, у меня был мандат на обеспечение:
- Он загружается мгновенно
- Он был надежным и имел предсказуемые рабочие характеристики
- Он работал полностью в автономном режиме
Mea culpa: Если вы посмотрите на код и запустите его в более старом браузере, есть вероятность, что он не сработает, я решил использовать ES6, но это не непреодолимое препятствие.
Если бы мы сосредоточились на создании опыта, который функционировал без включенного JavaScript, тогда он считает, что мы должны как можно больше отображать на сервере.
Наконец, у меня была второстепенная цель: я хотел изучить, насколько это возможно, чтобы делиться логикой между вашим Работодателем и сервером … Я говорю ложь, это то, что возбуждало меня больше всего и много преимуществ из прогрессивной истории выпало из-за этого.
Что было первым. Сервер или сервисный рабочий?
Это было одновременно. Я должен отображать с сервера, но поскольку рабочий службы находится между браузером и сетью, мне приходилось думать о том, как они взаимодействуют.
Я был в счастливой позиции, потому что у меня не было много уникальной логики сервера, поэтому я мог решать проблему целостно и одновременно. Принципы, которые я последовал, состояли в том, чтобы подумать о том, чего я хотел достичь, с первым рендерингом страницы (опытом, который получал каждый пользователь) и последующим отображением страницы (опыт, который привлекал пользователей), как с, так и без обслуживающий рабочий.
** Первый рендер ** & mdash; не было бы ни одного сервисного работника, поэтому мне нужно было убедиться, что первый рендер содержал как можно больше содержимого страницы и сгенерировал его на сервере.
Если у пользователя есть браузер, который поддерживает сервисного работника, тогда я могу сделать пару интересных вещей. У меня уже есть логика шаблона, созданная на сервере, и в них нет ничего особенного, тогда они должны быть теми же шаблонами, которые я буду использовать непосредственно на клиенте. Работник службы может получать шаблоны на oninstall и хранить их для последующего использования.
** Второй рендер без сервисного работника ** & mdash; Он должен действовать точно так же, как первый рендер. Мы можем извлечь выгоду из обычного HTTP-кэширования, но теория такая же: быстро переведите опыт.
** Второй рендеринг with service worker ** & mdash; Он должен действовать * точно * как первый рендер сервера, но все внутри рабочего. У меня нет традиционной оболочки. Если вы посмотрите на сеть, то все, что вы видите, - это полностью сшитое содержимое HTML: structure and content.

“Вывод” & quot; Потоковая передача - наш друг
Я старался быть настолько прогрессивным, насколько это возможно, что означает, что мне нужно максимально оперативно отображать на сервере. У меня возникла проблема, если бы я объединил все данные из всех RSS-каналов, тогда первый рендер будет заблокирован сетевыми запросами к RSS-каналам, и поэтому мы будем замедлять первый рендер.
Я выбрал следующий путь:
- Отобразить страницу страницы; он относительно статичен и быстро получает это на экране с превосходными характеристиками.
- Отобразить структуру страницы на основе конфигурации (столбцы) & mdash; для данного пользователя это в настоящее время статично и быстро становится видимым для пользователей.
- Извлеките данные столбца **, если ** у нас есть кешированный и доступный контент, мы можем сделать это как на сервере, так и на обслуживании
- Показывать нижний колонтитул страницы, содержащий логику, для динамического обновления содержимого страницы.
С учетом этих ограничений все должно быть асинхронным, и мне нужно как можно быстрее получить все в сети.
Существует реальная нехватка потоковых шаблонов библиотек в Интернете. Я использовал streaming-dot моим хорошим другом и коллегой Surma, который является портом шаблона шаблона doT, но с добавленными генераторами, чтобы он мог писать в Node или DOM Stream, а не блокировать все содержимое доступно.
Оказание данных столбца (то есть, что было в фиде) является самой важной частью, и на данный момент для клиента требуется JavaScript на клиенте для первой загрузки. Система настроена так, чтобы иметь возможность отображать все на сервере для первой загрузки, но я решил не блокировать в сети.
Если данные уже получены и доступны в обслуживающем персонале, мы можем быстро получить это для пользователя, даже если он может быстро стать устаревшим.
Код для рендеринга содержимого в то время как aysnc является относительно процедурным и следует модели, описанной ранее: мы представляем заголовок потоку, когда шаблон готов, а затем отображаем содержимое тела в поток, который, в свою очередь, может ждать содержимого, которое когда доступный также будет сброшен в поток, и, наконец, когда все будет готово, мы добавим нижний колонтитул и запустим его в поток ответов.
Ниже приведен код, который я использую на сервере и обслуживающий персонал.
const root = (dataPath, assetPath) => {
let columnData = loadData(`${dataPath}columns.json`).then(r => r.json());
let headTemplate = getCompiledTemplate(`${assetPath}templates/head.html`);
let bodyTemplate = getCompiledTemplate(`${assetPath}templates/body.html`);
let itemTemplate = getCompiledTemplate(`${assetPath}templates/item.html`);
let jsonFeedData = fetchCachedFeedData(columnData, itemTemplate);
/*
* Render the head from the cache or network
* Render the body.
* Body has template that brings in config to work out what to render
* If we have data cached let's bring that in.
* Render the footer - contains JS to data bind client request.
*/
const headStream = headTemplate.then(render => render({ columns: columnData }));
const bodyStream = jsonFeedData.then(columns => bodyTemplate.then(render => render({ columns: columns })));
const footStream = loadTemplate(`${assetPath}templates/foot.html`);
let concatStream = new ConcatStream;
headStream.then(stream => stream.pipeTo(concatStream.writable, { preventClose:true }))
.then(() => bodyStream)
.then(stream => stream.pipeTo(concatStream.writable, { preventClose: true }))
.then(() => footStream)
.then(stream => stream.pipeTo(concatStream.writable));
return Promise.resolve(new Response(concatStream.readable, { status: "200" }))
}
С этой моделью на самом деле было довольно просто получить вышеуказанный код и обработать работу на сервере * и * у рабочего.
Унифицированный логический сервер и логика рабочего агента & mdash; обручи и препятствия
Конечно, было нелегко добраться до общей кодовой базы между сервером и клиентом, экосистемой Node + NPM и экосистемой Web JS, как генетически идентичные близнецы, которые выросли в разных семьях, и когда они наконец встречаются, существует много сходств, и многие различия, которые нужно преодолеть … Это звучит как отличная идея для фильма.
Я предпочел использовать Web по всему проекту. Я решил это, потому что я не хочу связывать и загружать код в браузер пользователя, но я мог бы взять этот удар на сервере (я могу масштабировать его, пользователь не может), поэтому, если API wasn ‘ t поддерживается в узле, тогда мне нужно будет найти совместимую прокладку.
Вот некоторые из проблем, с которыми я столкнулся.
Сломанная модульная система
По мере роста как узла, так и веб-экосистемы они разработали различные способы компиляции, сегментации и импорта кода во время разработки. Это была настоящая проблема, когда я пытался построить этот проект.
Я не хотел использовать CommonJS в браузере. У меня есть иррациональное желание держаться подальше от как можно большего количества инструментов сборки и добавить в мое презрение к тому, как работает комплект, это оставило мне не много вариантов.
Моим решением в браузере было использовать плоский метод importScripts, он работает, но он зависит от очень специфического упорядочения файлов, как это видно у сервисного работника:
** sw.js **
importScripts(`/scripts/router.js`);
importScripts(`/scripts/dot.js`);
importScripts(`/scripts/platform/web.js`);
importScripts(`/scripts/platform/common.js`);
importScripts(`/scripts/routes/index.js`);
importScripts(`/scripts/routes/root.js`);
importScripts(`/scripts/routes/proxy.js`);
И затем для узла я использовал обычный механизм загрузки CommonJS в том же файле, но они заперты за простой оператор if для импорта модулей.
if (typeof module !== 'undefined' && module.exports) {
var doT = require('../dot.js');
...
Мое решение не является масштабируемым решением, оно сработало, но и забило мой код, ну код, который мне не нужен.
Я с нетерпением жду того дня, когда Node поддерживает «модули», которые браузеры будут поддерживать … Нам нужно что-то простое, разумное, общее и масштабируемое.
Если вы проверите код, вы увидите, что этот шаблон используется почти для каждого общего файла, и во многих случаях это было необходимо, потому что мне нужно было импортировать ссылку WHATWG reference reference reference.
Перекрещенные потоки
Потоки - это, пожалуй, самый важный примитив, который мы имеем при вычислении (и, вероятно, наименее понятном), и у обоих узлов, и в Сети есть свои совершенно разные решения. Это был кошмар в этом проекте, и нам действительно нужно стандартизировать единое решение (в идеале DOM Streams).
К счастью, существует полная реализация Streams API, которую вы можете подключить к узлу, и все, что вам нужно сделать, это написать пару утилит для отображения из Web Stream -> Node Stream и Node Stream -> Web Поток.
const nodeReadStreamToWHATWGReadableStream = (stream) => {
return new ReadableStream({
start(controller) {
stream.on('data', data => {
controller.enqueue(data)
});
stream.on('error', (error) => controller.abort(error))
stream.on('end', () => {
controller.close();
})
}
});
};
class FromWHATWGReadableStream extends Readable {
constructor(options, whatwgStream) {
super(options);
const streamReader = whatwgStream.getReader();
pump(this);
function pump(outStream) {
return streamReader.read().then(({ value, done }) => {
if (done) {
outStream.push(null);
return;
}
outStream.push(value.toString());
return pump(outStream);
});
}
}
}
Эти две вспомогательные функции использовались только в стороне узла этого проекта, и они были использованы, чтобы позволить мне получать данные в Node API, которые не могут принимать потоки WHATWG, а также передавать данные в API совместимых с WHATWG потоком, которые не понимают Node Streams , Я специально нуждался в этом для API fetch в узле.
После того, как я отсортировал Streams, окончательной проблемой и непоследовательностью была маршрутизация (по совпадению, именно там мне больше всего нужны Stream Utils).
Общая маршрутизация
Узловая экосистема, особенно Экспресс, невероятно хорошо известна и удивительно надежна, но у нас нет общей модели между клиентом и работником службы.
Несколько лет назад я написал LeviRoutes, простую библиотеку на стороне браузера, которая обрабатывала маршруты ExpressJS, а также подключалась к API истории, а также к API «onhashchange». Никто не использовал его, но я был счастлив. Мне удалось очистить паутину (сделать два или два) и развернуть ее в этом приложении. Посмотрев на приведенный ниже код, вы увидите, что моя маршрутизация - это то же самое.
** server.js **
app.get('/', (req, res, next) => {
routes['root'](dataPath, assetPath)
.then(response => node.responseToExpressStream(res, response));
});
app.get('/proxy', (req, res, next) => {
routes['proxy'](dataPath, assetPath, req)
.then(response => response.body.pipe(res, {end: true}));
})
** sw.js **
// The proxy server '/proxy'
router.get(`${self.location.origin}/proxy`, (e) => {
e.respondWith(routes['proxy'](dataPath, assetPath, e.request));
}, {urlMatchProperty: 'href'});
// The root '/'
router.get(`${self.location.origin}/$`, (e) => {
e.respondWith(routes['root'](dataPath, assetPath));
}, {urlMatchProperty: 'href'});
Я хотел бы увидеть единое решение, которое приведет API-интерфейс «onfetch» сервис-работника в узел.
Я также хотел бы увидеть «Express», как фреймворк, который унифицировал маршрутизацию запроса кода узла и браузера. Было достаточно разницы, что означало, что я не мог бы иметь один и тот же источник во всем мире. Мы можем обрабатывать маршруты почти точно так же на клиенте и на сервере, поэтому мы не так далеко.
Нет DOM вне рендера
Когда у пользователя нет обслуживающего сотрудника, логика для сайта довольно традиционная, мы отображаем сайт на сервере, а затем постепенно обновляем содержимое на странице с помощью традиционного опроса AJAX.
Логика использует API DOMParser, чтобы включить RSS-канал в то, что я могу фильтровать и запрашивать на странице.
// Get the RSS feed data.
fetch(`/proxy?url=${feedUrl}`)
.then(feedResponse => feedResponse.text())
// Convert it in to DOM
.then(feedText => {
const parser = new DOMParser();
return parser.parseFromString(feedText,'application/xml');
})
// Find all the news items
.then(doc => doc.querySelectorAll('item'))
// Convert to an array
.then(items => Array.prototype.map.call(items, item => convertRSSItemToJSON(item)))
// Don't add in items that already exist in the page
.then(items => items.filter(item => !!!(document.getElementById(item.guid))))
// DOM Template.
.then(items => items.map(item => applyTemplate(itemTemplate.cloneNode(true), item)))
// Add it into the page
.then(items => items.forEach(item => column.appendChild(item)))
Доступ к DOM в RSS-канале с использованием стандартных API-интерфейсов в браузере был невероятно полезным, и он позволил мне использовать мой собственный механизм шаблонов (который я очень горжусь) для динамического обновления страницы.
<template id='itemTemplate'>
<div class="item" data-bind_id='guid'>
<h3><span data-bind_inner-text='title'></span> (<a data-bind_href='link'>#</a>)</h3>
<div data-bind_inner-text='pubDate'></div>
</div>
</template>
<script>
const applyTemplate = (templateElement, data) => {
const element = templateElement.content.cloneNode(true);
const treeWalker = document.createTreeWalker(element, NodeFilter.SHOW_ELEMENT, () => NodeFilter.FILTER_ACCEPT);
while(treeWalker.nextNode()) {
const node = treeWalker.currentNode;
for(let bindAttr in node.dataset) {
let isBindableAttr = (bindAttr.indexOf('bind_') == 0) ? true : false;
if(isBindableAttr) {
let dataKey = node.dataset[bindAttr];
let bindKey = bindAttr.substr(5);
node[bindKey] = data[dataKey];
}
}
}
return element;
};
</script>Я был очень доволен собой, пока не понял, что я не могу использовать это на сервере или в сервисном работнике. Единственное решение, которое у меня было, - это ввести пользовательский XML-парсер и пройти его, чтобы сгенерировать HTML. Он добавил некоторые осложнения и оставил меня проклятием в Интернете.
В конечном итоге мне хотелось бы увидеть, что некоторые дополнительные API-интерфейсы DOM были добавлены рабочим, а также поддерживаются в узле, но решение, которое у меня есть, даже если оно не оптимально.
Является ли это возможным?
На этом посту есть два вопроса:
- Практично ли создавать системы совместно с общим сервером и обслуживающим персоналом?
- Можно ли создать полностью прогрессивное прогрессивное веб-приложение?
Насколько практично создавать системы совместно с общим сервером и сервисным работником?
Возможно, что системы используют общий сервер и обслуживающий персонал, но насколько это практично? Мне нравится идея, но я думаю, что ей нужно больше исследований, потому что, если вы собираетесь JS на всем пути, тогда существует много проблем между узловой и веб-платформой, которые необходимо сгладить.
Лично мне бы хотелось увидеть больше «Web» API в экосистеме узла.
Возможно ли построить полностью прогрессивное прогрессивное веб-приложение?
Да.
Я очень рад, что сделал это. Даже если вы не используете один и тот же язык на клиенте, как на службе, есть ряд важных вещей, которые, я думаю, я смог показать.
- AppShell - это не единственная модель, за которой вы можете следовать, важно то, что работник службы you получает контроль над сетью, и вы можете решить, что лучше всего подходит для вашего случая использования. 2. Можно создать прогрессивно реализованный опыт, который использует сервис-работника для обеспечения производительности и устойчивости (а также установленного ощущения, если хотите). Вы должны мыслить целостно, вам нужно начать с рендеринга как можно больше на сервере, а затем взять контроль над клиентом. 3. Можно подумать о опытах, которые создаются «триизоморфно» (я по-прежнему считаю, что лучше всего подходит термин изоморфный) с общей базой кода, общей структурой маршрутизации и общей логикой, разделяемой между клиентом, работником службы и сервером.
Я оставляю это как последнюю мысль: нам нужно больше исследовать, как мы хотим создавать прогрессивные веб-приложения, и нам нужно продолжать настаивать на шаблонах, которые позволят нам туда добраться. AppShell был отличным началом, это еще не конец. Прогрессивное рендеринг и улучшение являются ключом к долгосрочному успеху сети, никакая другая среда не может это сделать, как и в Интернете.
Если вас интересует код, проверьте его на Github, но вы также можете играть с ним прямо и пересобирать его на глюк


Paul Kinlan
Trying to make the web and developers better.




